Breaking Down Data Silos With a Unified Data Warehouse: An Apache Doris-Based CDP
An insurance company uses Apache Doris in replacement of Spark+Impala+HBase+NebulaGraph, in their Customer Data Platform for 4 times faster customer grouping.
Join the DZone community and get the full member experience.
Join For FreeThe data silos problem is like arthritis for online businesses because almost everyone gets it as they grow old. Businesses interact with customers via websites, mobile apps, H5 pages, and end devices. For one reason or another, it is tricky to integrate the data from all these sources. Data stays where it is and cannot be interrelated for further analysis. That's how data silos come to form. The bigger your business grows, the more diversified customer data sources you will have, and the more likely you are trapped by data silos.
This is exactly what happens to the insurance company I'm going to talk about in this post. By 2023, they have already served over 500 million customers and signed 57 billion insurance contracts. When they started to build a customer data platform (CDP) to accommodate such a data size, they used multiple components.
Data Silos in CDP
Like most data platforms, their CDP 1.0 had a batch processing pipeline and a real-time streaming pipeline. Offline data was loaded, via Spark jobs, to Impala, where it was tagged and divided into groups. Meanwhile, Spark also sent it to NebulaGraph for OneID computation (elaborated later in this post). On the other hand, real-time data was tagged by Flink and then stored in HBase, ready to be queried.
That led to a component-heavy computation layer in the CDP: Impala, Spark, NebulaGraph, and HBase.
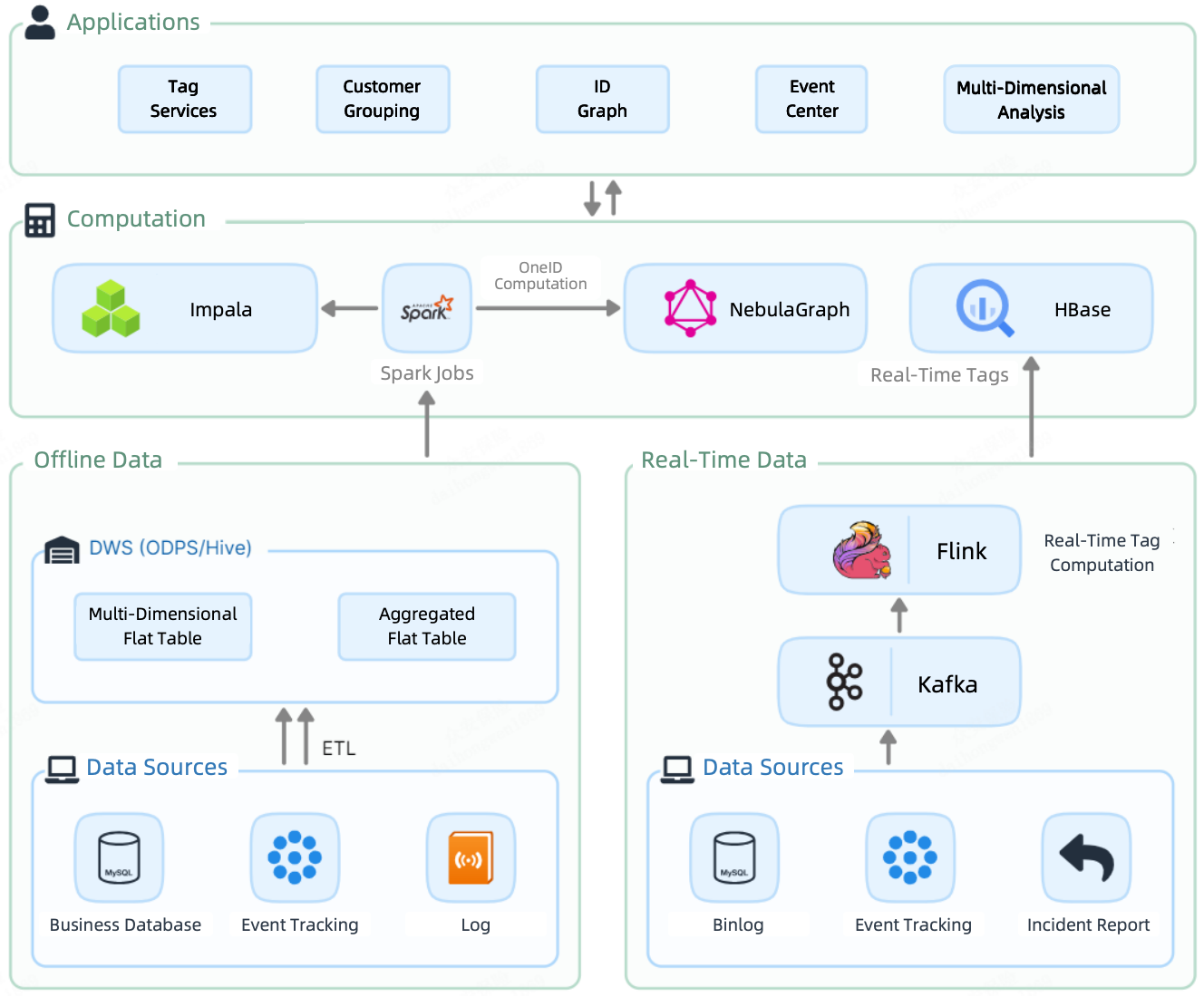
As a result, offline tags, real-time tags, and graph data were scattered across multiple components. Integrating them for further data services was costly due to redundant storage and bulky data transfer. What's more, due to discrepancies in storage, they had to expand the size of the CDH cluster and NebulaGraph cluster, adding to the resource and maintenance costs.
Apache Doris-Based CDP
For CDP 2.0, they decide to introduce a unified solution to clean up the mess. At the computation layer of CDP 2.0, Apache Doris undertakes both real-time and offline data storage and computation.
To ingest offline data, they utilize the Stream Load method. Their 30-thread ingestion test shows that it can perform over 300,000 upserts per second. To load real-time data, they use a combination of Flink-Doris-Connector and Stream Load. In addition, in real-time reporting where they need to extract data from multiple external data sources, they leverage the Multi-Catalog feature for federated queries.
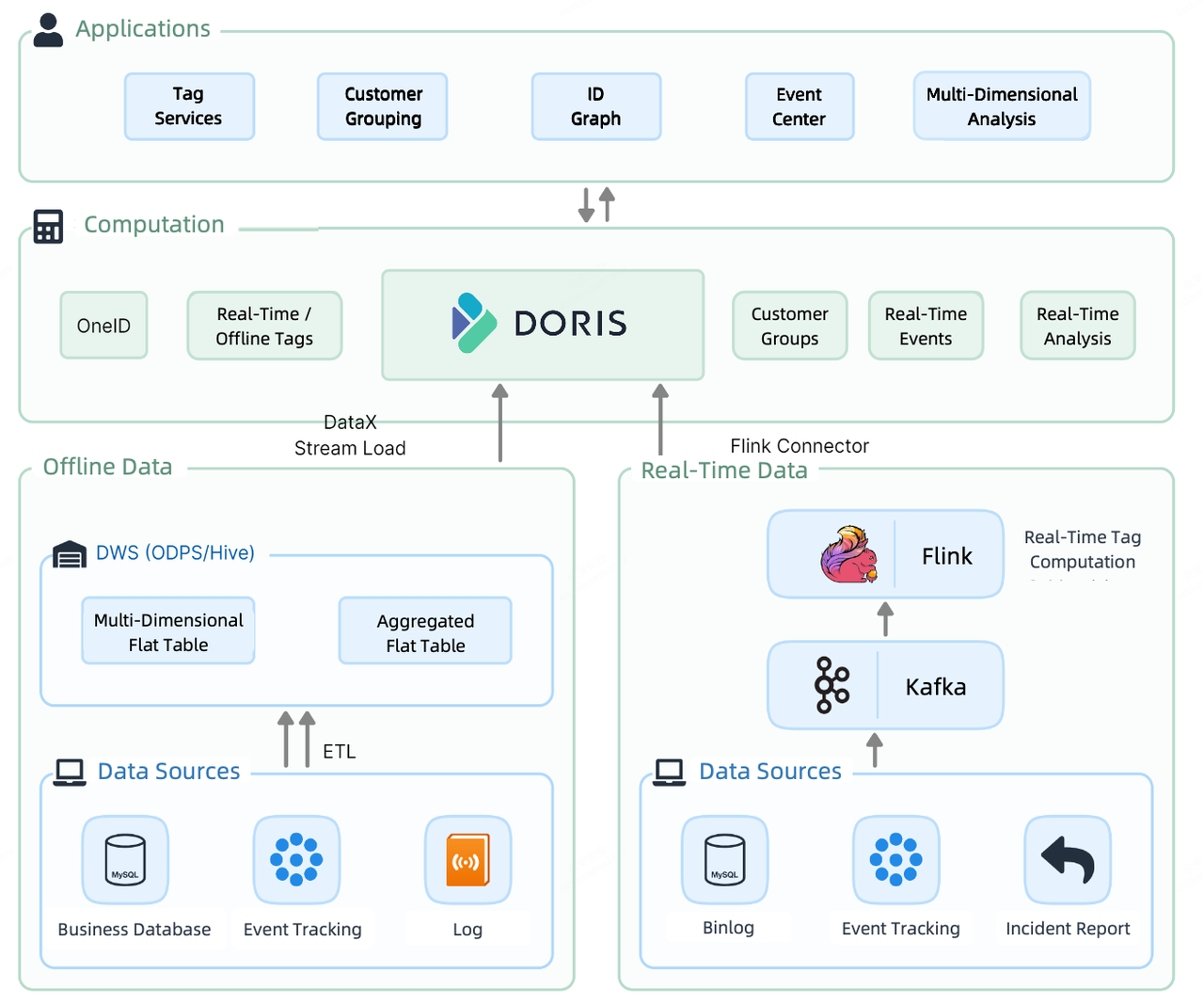
The customer analytic workflows on this CDP go like this. First, they sort out customer information, then they attach tags to each customer. Based on the tags, they divide customers into groups for more targeted analysis and operation.
Next, I'll delve into these workloads and show you how Apache Doris accelerates them.
OneID
Has this ever happened to you when you have different user registration systems for your products and services? You might collect the email of UserID A from one product webpage, and later the social security number of UserID B from another. Then you find out that UserID A and UserID B actually belong to the same person because they go by the same phone number.
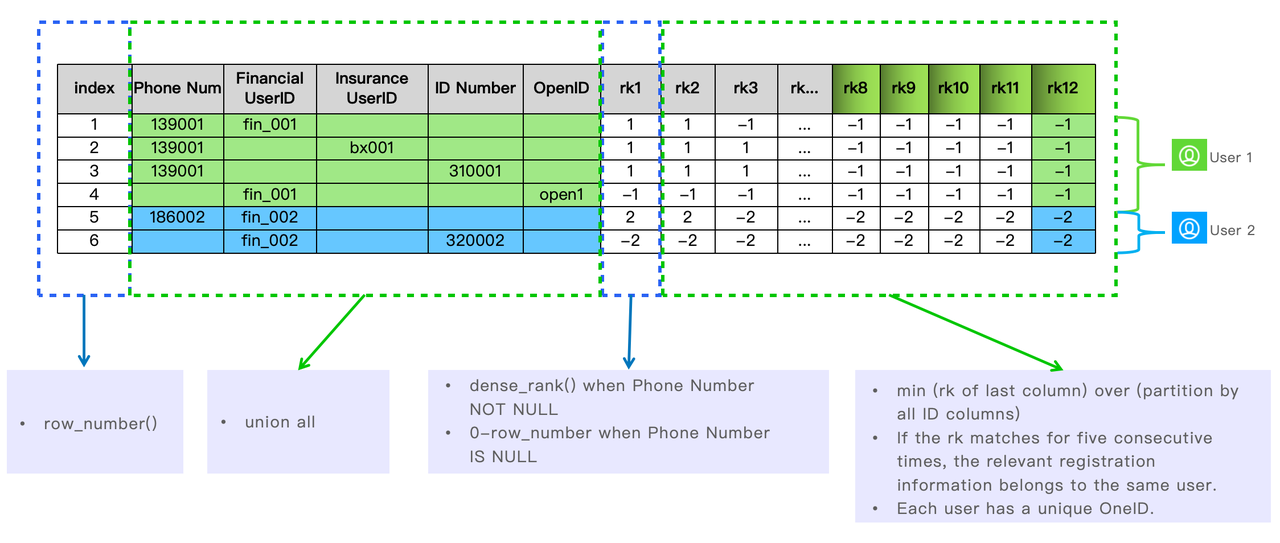
That's why OneID arises as an idea. It is to pool the user registration information of all business lines into one large table in Apache Doris, sort it out, and make sure that one user has a unique OneID.
This is how they figure out which registration information belongs to the same user leveraging the functions in Apache Doris.
Tagging Services
This CDP accommodates information of 500 million customers, which come from over 500 source tables and are attached to over 2000 tags in total.
By timeliness, the tags can be divided into real-time tags and offline tags. The real-time tags are computed by Apache Flink and written into the flat table in Apache Doris, while the offline tags are computed by Apache Doris as they are derived from the user attribute table, business table, and user behavior table in Doris. Here is the company's best practice in data tagging:
1. Offline Tags
During the peaks of data writing, a full update might easily cause an OOM error given their huge data scale. To avoid that, they utilize the INSERT INTO SELECT function of Apache Doris and enable partial column update. This will cut down memory consumption by a lot and maintain system stability during data loading.
set enable_unique_key_partial_update=true;
insert into tb_label_result(one_id, labelxx)
select one_id, label_value as labelxx
from .....2. Real-Time Tags
Partial column update is also available for real-time tags since even real-time tags are updated at different paces. All that is needed is to set partial_columns to true.
curl --location-trusted -u root: -H "partial_columns:true" -H "column_separator:," -H "columns:id,balance,last_access_time" -T /tmp/test.csv http://127.0.0.1:48037/api/db1/user_profile/_stream_load3. High-Concurrency Point Queries
With its current business size, the company is receiving query requests for tags at a concurrency level of over 5000 QPS. They use a combination of strategies to guarantee high performance. Firstly, they adopt Prepared Statement for pre-compilation and pre-execution of SQL. Secondly, they fine-tune the parameters for Doris Backend and the tables to optimize storage and execution. Lastly, they enable row cache as a complement to the column-oriented Apache Doris.
Fine-tune Doris' Backend parameters in
be.conf:
disable_storage_row_cache = false
storage_page_cache_limit=40%
Fine-tune table parameters upon table creation:
enable_unique_key_merge_on_write = true
store_row_column = true
light_schema_change = true
4. Tag Computation (Join)
In practice, many tagging services are implemented by multi-table joins in the database. That often involves more than 10 tables. For optimal computation performance, they adopt the colocation group strategy in Doris.
Customer Grouping
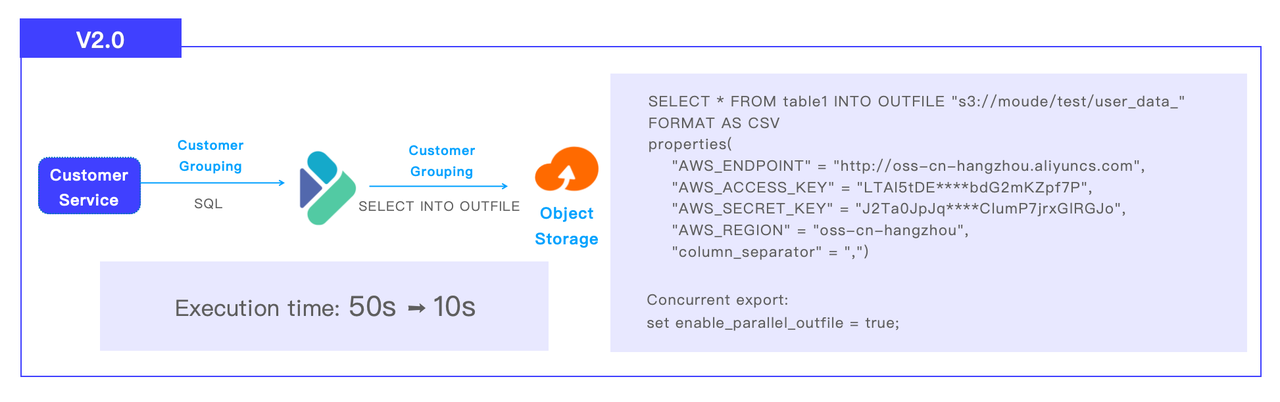
The customer grouping pipeline in CDP 2.0 goes like this: Apache Doris receives SQL from customer service, executes the computation, and sends the result set to S3 object storage via SELECT INTO OUTFILE. The company has divided its customers into 1 million groups. The customer grouping task that used to take 50 seconds in Impala to finish now only needs 10 seconds in Doris.
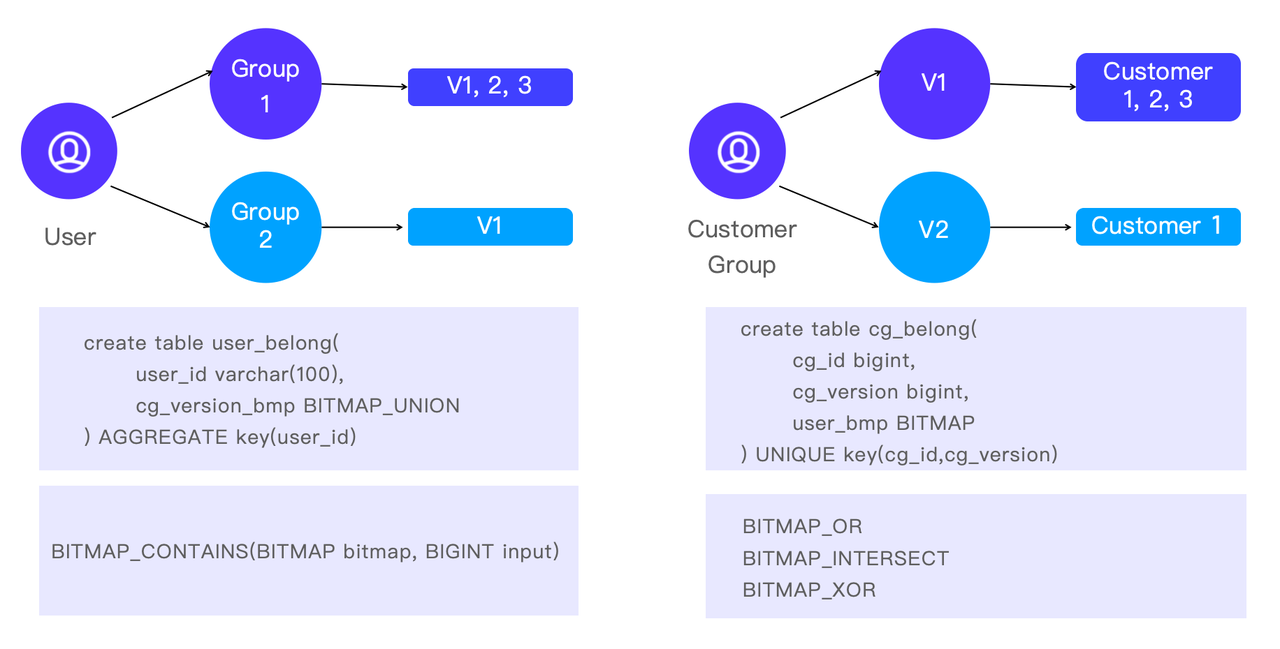
Apart from grouping the customers for more fine-grained analysis, sometimes they do analysis in a reverse direction. That is, to target a certain customer and find out to which groups he/she belongs. This helps analysts understand the characteristics of customers as well as how different customer groups overlap.
In Apache Doris, this is implemented by the BITMAP functions: BITMAP_CONTAINS is a fast way to check if a customer is part of a certain group, and BITMAP_OR, BITMAP_INTERSECT, and BITMAP_XOR are the choices for cross-analysis.
Conclusion
From CDP 1.0 to CDP 2.0, the insurance company adopts Apache Doris, a unified data warehouse, to replace Spark+Impala+HBase+NebulaGraph. That increases their data processing efficiency by breaking down the data silos and streamlining data processing pipelines. In CDP 3.0, they want to group their customer by combining real-time tags and offline tags for more diversified and flexible analysis. The Apache Doris community and the VeloDB team will continue to be a supporting partner during this upgrade.
Published at DZone with permission of Frank Z. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments