Collaborative Development of New Features With Microservices
We’ll highlight the advantages of solving this problem and introduce an efficient way to streamline parallel feature development.
Join the DZone community and get the full member experience.
Join For FreeIn a microservices architecture, code is broken into small units. These pieces of code can be developed in isolation and shipped independently to production, which reduces dependencies between teams—the result: is rapid feature development and faster time to market.
While a microservices architecture brings many benefits, the reality is that these benefits tend to diminish at scale. In particular, the more microservices that an organization has, the harder it is to ensure that changes work together as a whole.
Collaborating and iterating earlier on service API contracts makes the process much faster and more efficient. Understanding how to overcome challenges involved with collaboration across service boundaries is critical for growing organizations that need their microservices architecture to scale. Here, we’ll highlight the advantages of solving this problem and introduce an efficient way to streamline parallel feature development.
Monoliths vs. Microservices
Microservices-based architectures have become increasingly common in large part because a monolithic code base can be extremely difficult and costly to scale.
For example, with a monolith:
- Changes aren’t deployed quickly because developers can’t work independently.
- End-user behavior can’t be tested continuously; instead, it’s tested using a more time-consuming waterfall model.
- A problem with one part of the code can affect or break the entire application.
- Every time an issue is found, the code may need to be rolled back because it’s not always clear which commit caused the break.
- The more changes, the greater the number, size, and severity of the software regressions, further complicating testing.
Testing an application as a whole instead of testing pieces of that application along the way slows down development. With microservices, smaller pieces of code can be independently developed, tested, deployed, and updated, eliminating many of the bottlenecks that occur with monoliths and reducing risks.
In addition, parallel feature development allows multiple changes to be released simultaneously. The ability to make smaller changes independently gives developers autonomy and flexibility, reduces troubleshooting time, and speeds deployment. As a result, applications become more stable and resilient in turn.
Microservices and Dependencies
A microservices architecture can foster a more rapid, cost-effective, agile delivery model. However, a microservices architecture can also have its share of challenges.
Components and services may act as independent, isolated units in a microservices architecture but still, have dependencies. Each unit of code communicates with other units of code to exchange data and information using well-defined APIs that make external calls. While microservices reduce dependencies as a general rule, the greater the number of microservices, the greater the number of dependencies.
While these dependencies don’t necessarily affect unit testing, they do affect the in-depth testing that needs to occur at the API boundaries. In addition, testing the interaction between microservices can slow the development process, as developers traditionally spend a lot of time debugging issues across boundaries. Finally, these dependencies can be particularly hard to manage when the number of dependencies increases to tens or hundreds of microservices. Software delivery speed is often impacted as a result.
Microservices and Collaboration
New feature development typically involves changes to multiple services, and developers need to collaborate across service boundaries in order to define and test APIs that other teams will consume. This collaboration gets tricky when developers can’t integrate with dependent services early in the development life cycle.
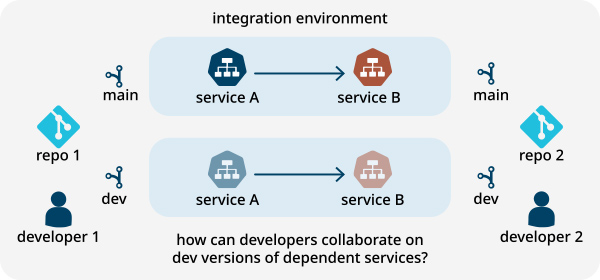
The most common way to address this problem is to merge independent changes, deploy all changes to a staging environment, and preview and test the feature on staging. However, each iteration cycle involves troubleshooting on a shared staging environment, reproducing issues locally, and going through a CI/CD workflow. This slow process impedes collaboration and parallel feature development.
Moreover, as multiple teams build features concurrently, using a shared staging environment becomes a bigger problem. Any bugs that are introduced impact other teams that rely on the shared environment, which limits the number of features that can be developed in parallel at any one time.
As workarounds, some organizations clone multiple copies of a staging environment to create a pool of environments or timeshare a single environment across many teams/features. Unfortunately, the former approach typically incurs a substantial cost increase, and the latter presents a bottleneck as the time waiting for the environment to be available increases.
Scaling Environments for Microservices
The key to improving engineering productivity around new feature development is to provide fast and high-quality feedback throughout the software development life cycle. However, the inability to scale environments that enable shift-left testing causes the challenges above with dependencies and collaboration. In addition, cloning environments is cost-prohibitive, so a new approach to multi-tenant environments is needed.
A new approach to scaling environments cost-effectively is to use application-level multi-tenancy to create a large number of high-fidelity environments that exist in parallel. Instead of isolating infrastructure, this approach isolates requests by labeling and dynamically routing traffic. We refer to this model as Sandbox environments.

Using Sandbox environments, teams can create many high-fidelity environments within one physical Kubernetes cluster without the infrastructure expense or operational burden of duplicating physical environments. In this model, the baseline environment that is continuously updated by a CI/CD process is shared safely between all the Sandboxes.
The Sandbox model of environments has many benefits:
- It’s cost-effective. Each environment uses minimal resources, enabling hundreds or even thousands of lightweight, ephemeral environments to be created.
- It’s fast. Each environment spins up in seconds.
- It ensures testing is valid. The “under-test” versions of services are always tested against the baseline, which is continuously being updated.
- It promotes early collaboration. Developers working across code repositories can collaborate by rapidly publishing and consuming new API changes.
Greater Scalability With Sandbox Environments
Access to Sandbox environments pre-merge makes for very fast iterations and collaboration across API boundaries without waiting for slow CI/CD workflows. Not surprisingly, many leading companies, including Uber, Lyft, and DoorDash, use Sandbox solutions to build microservices at scale.
Without Sandbox Environments |
With Sandbox Environments |
Developers commit changes to their main branch, deploy to a staging environment, and test their changes end to end. Developers must follow this complex testing process whenever they change their services. Challenges include:
|
Developers commit changes to their feature branches and test their changes end to end using high-fidelity Sandbox environments. Developers can perform feature, regression, and usability testing using shared resources on an ongoing basis. Benefits include:
|
Because isolation is built into high-fidelity Sandbox environments, developers can make changes independently, collaborate on API development and testing, and quickly consume each other’s changes. Features can be tested pre-merged, and problems can be discovered and corrected with fast feedback loops.
Today, teams need to scale the number of environments to support parallel feature development, particularly as the number of microservices increases. While the traditional approach of cloning environments is not cost-effective, this new Sandbox approach changes the microservices collaboration and testing paradigm. Sandbox environments enable parallel feature development, promote collaboration across teams, and are cost-effective to scale, which is why their use is becoming increasingly common in large and small organizations.
Opinions expressed by DZone contributors are their own.
Comments