Why Real-time Data Integration Is a Priority for Architects in the Modern Era
The importance of change data capture in distributed architectures. Explore the complexity of data integration, open-source solutions, anti-patterns, and best practices.
Join the DZone community and get the full member experience.
Join For FreeStaying ahead of the curve in today's quickly expanding digital landscape is more than a goal—it's a requirement. For architects, mastering real-time data integration consequently becomes indispensable, and the reason is clear: modern businesses crave instantaneous insights, fluid user experiences, and the agility to adapt strategies on the fly.
This is why Change Data Capture (CDC) has become increasingly important in the field of architecture. It allows for the continuous integration of data changes from/to various sources, ensuring that systems are always up-to-date.
To get started, we'll explore the technologies that power CDC, Kafka, and Debezium. Learning about their capabilities and the challenges they solve should clarify why the CDC represents an effective approach to data integration. After that, we'll explore anti-patterns in data integration, architectural considerations, and trade-offs.
Exploring The Foundations of CDC: Kafka, Debezium
Apache Kafka is a distributed event streaming technology designed to handle massive amounts of data, making it perfect for real-time analytics and monitoring. Debezium, on the other hand, is an open-source platform for change data capture (CDC). It can capture and stream all database changes in real time, eliminating the need for batch processing and enabling services to react immediately to data changes.
This synergy between Kafka and Debezium eliminates batch-processing bottlenecks, enabling solutions to respond instantly to fast-moving data changes.
To facilitate the understanding of this data integration strategy, picture the scenario, for instance, of an e-commerce platform. In this case, Debezium could be used to capture changes in the inventory database and stream them to Kafka topics. The data can then be consumed by various systems, such as a real-time inventory management application, a recommendation engine, and a dashboard for monitoring stock levels.
A Closer Look at Debezium
Debezium's greatest value comes from its ability to tap into a database's transaction logs, capture changes as they occur, and streaming them as events in real time. To facilitate understanding and know what to expect, check the following examples of events that would be emitted if Debezium captured operations of insert, update, and delete on a database being tracked. Sample of an Event Emitted for a db operation of:
- Insert:
{
"before": null,
"after": {
"id": 1,
"name": "John",
"age": 25
},
"source": {
"table": "users",
"schema": "public",
"database": "mydatabase"
},
"op": "c"
}- Update:
{
"before": {
"id": 1,
"name": "John",
"age": 25
},
"after": {
"id": 1,
"name": "John Doe",
"age": 30
},
"source": {
"table": "users",
"schema": "public",
"database": "mydatabase"
},
"op": "u"
}- Delete:
{
"before": {
"id": 1,
"name": "John Doe",
"age": 30
},
"after": null,
"source": {
"table": "users",
"schema": "public",
"database": "mydatabase"
},
"op": "d"
}From the above examples, see that there different events will be emitted for create, update, and delete. Each holds information about the changes of a specific record in the tracked database.
- The "
before" field shows the state of the record before the change, - The "
after" field shows the state of the record after the change, - and the "
op" field indicates the type of operation performed. - The "
source" field brings the details about the table, schema, and database where the change occurred.
Debezium's extensive compatibility with multiple database vendors further expands its capabilities, making it a flexible and versatile technology. It works under the covers using Kafka Connect and two core connector types:
- Source: connectors that can read data from some type of data source, transform, and emit them individually as events. Debezium is an example of a Source Connector. At the time of writing, Debezium offers connectors for MongoDB, MySQL, PostgreSQL, SQL Server, Oracle Db2, Cassandra, and under preview for Vitess, Spanner, and JDBC.
- Sink: connectors that can consume data from specified topics and send them to the determined data store type.
Debezium has a new interesting feature currently under preview to support users on creating, maintaining, and visualizing configurations using a web UI:
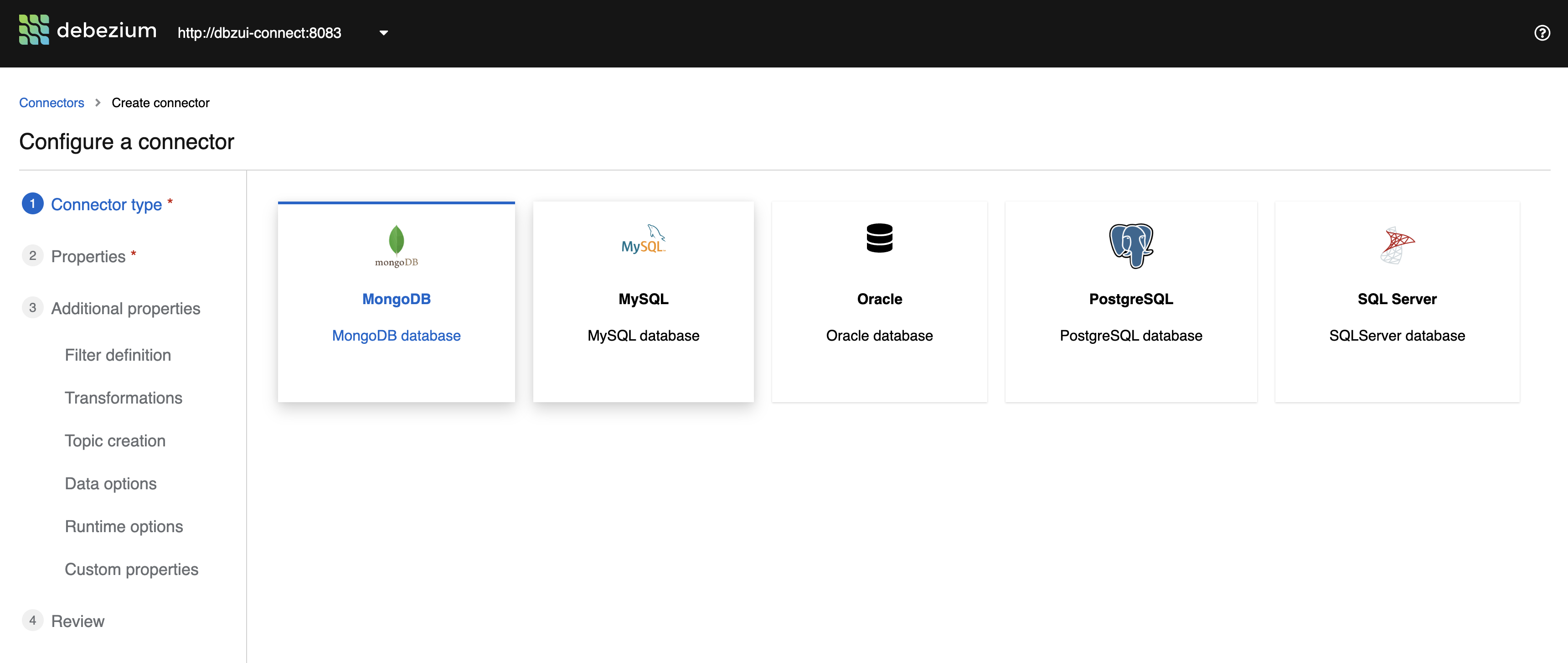
Additionally, Debezium has monitoring and error-handling capabilities to ensure that data is consistently and reliably streamed. The way it technically handles errors is by using a combination of messaging retry mechanisms and dead-letter queues (DLQs). When an error occurs during data streaming, Debezium retries the operation a certain number of times before forwarding it to a dead-letter queue. This ensures that no data is lost and provides a troubleshooting path for fixing the underlying issue.
Architectural Considerations
When deploying CDC, architects must be aware of the following:
- Data Transformation: Integration solutions, like Kafka streams, can process and transform events published by Debezium, enabling data enrichment, filtering, or aggregation before publishing events to other systems in the architecture.
- Messaging System Requirements: You'll need a reliable and scalable messaging system to handle the high volume of data changes being captured and processed. The messaging system should be able to handle both real-time and batch-processing scenarios, as well as support different data formats and protocols.
- Distributed Storage: A distributed storage mechanism is essential to store and manage the captured change data, ensuring high availability and resilience.
- Consider Cloud Services: Cloud service providers offer integrated messaging and storage solutions tailored for CDC. That can help in case of a lack of specialized technical professionals on the platform and infrastructure's requirements and serving as a simpler means to service scalability and cost-efficiency.
Common Errors and Anti-patterns in Data Management for Distributed Services
The adoption of microservice architectures can introduce unique challenges regarding handling data in a distributed environment. Common pitfalls include:
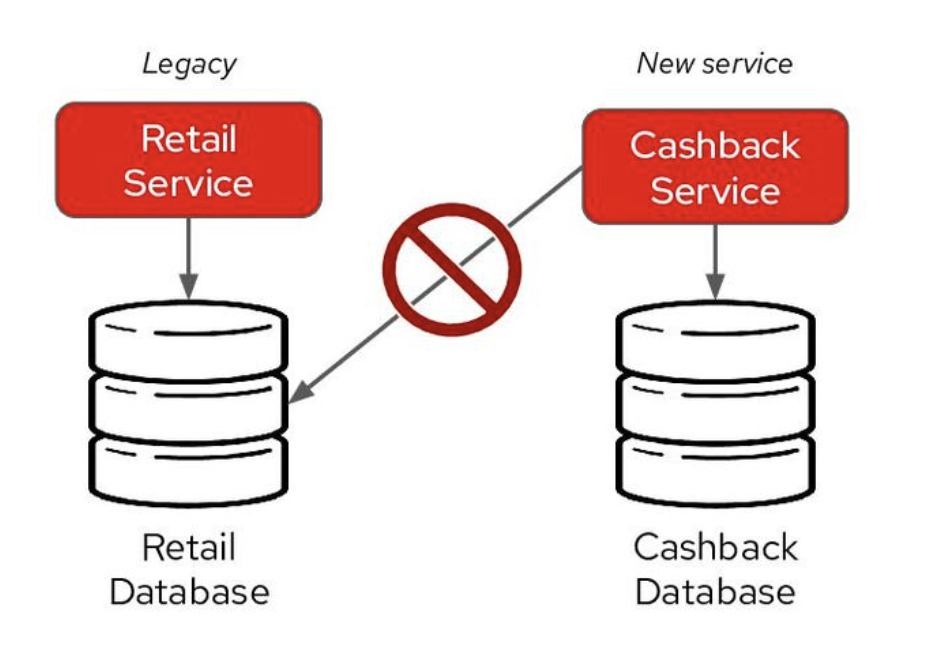
- Shared Databases: Multiple microservices interacting with a single shared database can lead to tightly-coupled services. CDC can help ensure each microservice possesses its own data view and by preserving data encapsulation.
![]()
- Dual writes: In distributed systems, some services can update data in its own database and external data stores, such as ElasticSearch. This is an issue as the core data operations are no longer handled in transactions. This can lead to data inconsistency in distributed systems.

- Inconsistent Data Models: Data inconsistency may happen when different services use different data models for the same data entity. CDC can act as a gateway, catching changes in the source data and distributing it to other services using a consistent model.
- Ignoring Eventual Consistency: Don't expect immediate data consistency across distributed services. The way CDC helps addressing this gap is that all services will, at last, get a consistent view of the data.
- No Proper Handling of Data Evolution: Without a data evolution plan, changes can become confusing, risky, and time-consuming. CDC solutions, particularly when integrated with platforms such as Kafka, can elegantly take into account schema evolution.
CDC Adoption Is on the Rise
CDC initially gained traction as an alternative to batch data replication for populating data warehouses for Extract, Transform, and Load (ETL) procedures. With the increasing adoption of cloud-native architectures plus the need for real-time analytics, the role of this integration pattern has never been more important. It's not only about data replication; it's about real-time data integration, ensuring services can access and provide the correct data at the right time.
With the emergence of technologies like AI and machine learning, the need for real-time data has increasingly grown. Architects must examine not only how to acquire and analyze data but also how to do so in a scalable, reliable, and cost-effective way.
This is where the CDC (Change Data Capture) comes into play. It allows organizations to capture and replicate only the changes made to their data rather than transferring the entire dataset, significantly reducing the time and resources required for data integration and making it a more efficient and practical solution for handling large volumes of data.
Wrapping It Up
The importance of real-time data integration cannot be underestimated in today's fast-paced and data-driven world. As organizations continue to embrace advanced technologies and rely on accurate data, architects own the important responsibility of designing systems that can handle the increasing demands for data processing and analysis. By prioritizing scalability, reliability, and cost-effectiveness, architects can ensure their organizations have the tools to make informed decisions and stay competitive in their respective industries.
Debezium and Kafka are two popular technologies for architecting distributed Java microservices. By incorporating these open-source technologies, architects can create solutions with seamless integration and processing of data across microservices, harnessing the power of real-time data integration and processing.
Opinions expressed by DZone contributors are their own.
Comments