
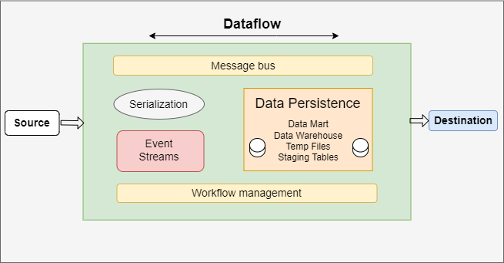
What Is a Data Pipeline?
A data pipeline comprises a collection of tools and processes for efficient transfer, storage, and processing of data across multiple systems. With data pipelines, organizations can automate information extraction from distributed sources while consolidating data into high-performance storage for centralized access. A data pipeline essentially forms the foundation to build and manage analytical tools for critical insights and strategic business decisions. By building reliable pipelines for the consolidation and management of data flows, development and DataOps teams can also efficiently train, analyze, and deploy machine learning models.
Data Pipeline Types
Data pipelines are broadly categorized into the following types:
Batch Pipelines
In batch pipelines, data sets are collected over time in batches and then fed into storage clusters for future use. These pipelines are mostly considered applicable for legacy systems that cannot deliver data in streams, or in use cases that deal with colossal amounts of data. Batch pipelines are usually deployed when there’s no need for real-time analytics and are popular for use cases such as billing, payroll processing, and customer order management.
Streaming Pipelines
In contrast to batch pipelines, streaming data pipelines continuously ingests data, processing it as soon as it reaches the storage layer. Such pipelines rely on highly efficient frameworks that support the ingestion and processing of a continuous stream of data within a sub-second time frame. As a result, stream data pipelines are mostly suitable for operations that require quicker analysis and real-time insights of smaller data sets. Typical use cases include social media engagement analysis, log monitoring, traffic management, user experience analysis, and real-time fraud detection.
Data Pipeline Processes
Though the underlying framework of data pipelines differ based on use cases, they mostly rely on a number of common processes and elements for efficient data flow. Some key processes of data pipelines include:
Sources
In a data pipeline, a source acts as the first point of the framework that feeds information into the pipeline. These include NoSQL databases, application APIs, cloud sources, Apache Hadoop, relational databases, and many more.
Joins
A join represents an operation that enables the establishment of a connection between disparate data sets by combining tables. While doing so, join specifies the criteria and logic for combining data from different sources into a single pipeline.
Joins in data processing are categorized as:
- INNER Join — Retrieves records whose values match in both tables
- LEFT (OUTER) Join — Retrieves all records from the left table plus matching values from the right table
- RIGHT (OUTER) Join — Retrieves all records from the right table plus matching records from the left table
- FULL (OUTER) Join — Retrieves all records, whether there is a match or not in any of the two tables. In SQL tables with star schema, full joins are typically implemented through conformed dimensions to link fact tables, creating fact-to-fact joins.
Extraction
Source data remains in a raw format that requires processing for further analysis. Extraction is the first step of data ingestion where the data is crawled and analyzed to ensure information relevancy before it is passed to the storage layer for transformation.
Standardization
Once data has been extracted, it is converted into a uniform format that enables efficient analysis, research, and utilization. Standardization is the process of formulating data with disparate variables on the same scale to enable easier comparison and trend analysis. Data standardization is commonly used for attributes such as dates, units of measure, color, size, etc.
Correction
This process involves cleansing the data to eliminate errors and pattern anomalies. When performing correction, data engineers typically use rules to identify a violation of data expectation, then modify it to meet the organization’s needs. Unaccepted values can then be ignored, reported, or cleansed according to pre-defined business or technical rules.
Loads
Once data has been extracted, standardized, and cleansed, it is loaded into the destination system, such as a data warehouse or relational database, for storage or analysis.
Automation
Data pipelines often involve multiple iterations of administrative and executive tasks. Automation involves monitoring the workflows to help identify patterns for scheduling tasks and executing them with minimal human intervention. Comprehensive automation of a data pipeline also involves the detection of errors and notification mechanisms to maintain consistent data sanity.
{{ parent.title || parent.header.title}}
{{ parent.tldr }}
{{ parent.linkDescription }}
{{ parent.urlSource.name }}