Data Pipeline Using MongoDB and Kafka Connect on Kubernetes
Learn how you can run Kafka Connect on Kubernetes to create data pipelines using MongoDB
Join the DZone community and get the full member experience.
Join For FreeIn Kafka Connect on Kubernetes, the easy way!, I had demonstrated Kafka Connect on Kubernetes using Strimzi along with the File source and sink connector. This blog will showcase how to build a simple data pipeline with MongoDB and Kafka with the MongoDB Kafka connectors, which will be deployed on Kubernetes with Strimzi.
I will be using the following Azure services:
Please note that there are no hard dependencies on these components, and the solution should work with alternatives as well
- Azure Event Hubs for Apache Kafka (any other Kafka cluster should work fine)
- Azure Kubernetes Service (feel free to use
minikube,kindetc.) - Azure Cosmos DB as the MongoDB database, thanks to Azure Cosmos DB's API for MongoDB
In this tutorial, Kafka Connect components are being deployed to Kubernetes, but it is also applicable to any Kafka Connect deployment
What's covered?
- MongoDB Kafka Connector and Strimzi overview
- Azure specific (optional) - Azure Event Hubs, Azure Cosmos DB and Azure Kubernetes Service
- Setup and operate Source and Sink connectors
- Test end to end scenario
All the artifacts are available on GitHub
Overview
Here is an overview of the different components:
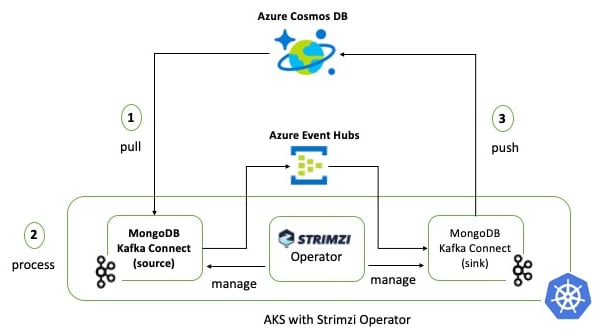{kind=link}
I have used a contrived/simple example in order to focus on the plumbing, moving parts
MongoDB Kafka Connector(s)
The MongoDB Kafka Connect integration provides two connectors: Source and Sink
- Source Connector: It pulls data from a
MongoDBcollection (that acts as asource) and writes them to Kafka topic - Sink connector: It is used to process the data in Kafka topic(s), persist them to another MongoDB collection (thats acts as a
sink)
These connectors can be used independently as well, but in this blog, we will use them together to stitch the end-to-end solution
Strimzi overview
Strimzi simplifies the process of running Apache Kafka in a Kubernetes cluster by providing container images and Operators for running Kafka on Kubernetes. It is a part of the Cloud Native Computing Foundation as a Sandbox project (at the time of writing)
Strimzi Operators are fundamental to the project. These Operators are purpose-built with specialist operational knowledge to effectively manage Kafka. Operators simplify the process of: Deploying and running Kafka clusters and components, Configuring and securing access to Kafka, Upgrading and managing Kafka and even taking care of managing topics and users.
Prerequisites
kubectl - https://kubernetes.io/docs/tasks/tools/install-kubectl/
If you choose to use Azure Event Hubs, Azure Kubernetes Service or Azure Cosmos DB you will need a Microsoft Azure account. Go ahead and sign up for a free one!
Azure CLI or Azure Cloud Shell - you can either choose to install the Azure CLI if you don't have it already (should be quick!) or just use the Azure Cloud Shell from your browser.
Helm
I will be using Helm to install Strimzi. Here is the documentation to install Helm itself - https://helm.sh/docs/intro/install/
You can also use the
YAMLfiles directly to installStrimzi. Check out the quick start guide here - https://strimzi.io/docs/quickstart/latest/#proc-install-product-str
Let's start by setting up the required Azure services (if you're not using Azure, skip this section but please ensure you have the details for your Kafka cluster i.e. broker URLs and authentication credentials, if applicable)
I recommend installing the below services as a part of a single Azure Resource Group which makes it easy to clean up these services
Azure Cosmos DB
You need to create an Azure Cosmos DB account with the MongoDB API support enabled along with a Database and Collection. Follow these steps to setup Azure Cosmos DB using the Azure portal:
- Create an Azure Cosmos DB account
- Add a database and collection and get the connection string
Learn more about how to Work with databases, containers, and items in Azure Cosmos DB
If you want to use the Azure CLI or Cloud Shell, here is the sequence of commands which you need to execute:
Create an Azure Cosmos DB account (notice --kind MongoDB)
az cosmosdb create --resource-group <RESOURCE_GROUP> --name <COSMOS_DB_NAME> --kind MongoDB
az cosmosdb mongodb database create --account-name <COSMOS_DB_ACCOUN> --name <COSMOS_DB_NAME> --resource-group <RESOURCE_GROUP>
Finally, create a collection within the database
az cosmosdb mongo collection create --account-name <COSMOS_DB_ACCOUNT> --database-name <COSMOS_DB_NAME> --name <COSMOS_COLLECTION_NAME> --resource-group-name <RESOURCE_GROUP> --shard <SHARDING_KEY_PATH>
Get the connection string and save it. You will be using it later
az cosmosdb list-connection-strings --name <COSMOS_DB_ACCOUNT> --resource-group <RESOURCE_GROUP> -o tsv --query connectionStrings[0].connectionString
Seed the collection with some data. There are many ways you could do this. For the purposes of this tutorial, I would recommend quick and easy, such as:
- The
Data Explorertab available in the Azure portal (when you create an Azure Cosmos DB account) - Azure Cosmos DB explorer (a standalone web-based interface )
- Native Mongo shell (via the Data Explorer tab in Azure Portal)
Later on, when we deploy the source connector, we will double check to see if these (existing) items/records are picked up by the connector and sent to Kafka
Azure Event Hubs
Azure Event Hubs is a data streaming platform and event ingestion service and it also provides a Kafka endpoint that can be used by existing Kafka based applications as an alternative to running your own Kafka cluster. Event Hubs supports Apache Kafka protocol 1.0 and later, and works with existing Kafka client applications and other tools in the Kafka ecosystem including Kafka Connect (demonstrated in this blog), MirrorMaker etc.
To setup an Azure Event Hubs cluster, you can choose from a variety of options including the Azure portal, Azure CLI, Azure PowerShell or an ARM template. Once the setup is complete, you will need the connection string (that will be used in subsequent steps) for authenticating to Event Hubs - use this guide to finish this step.
Please ensure that you also create an Event Hub (same as a Kafka topic) to act as the target for our Kafka Connect connector (details in subsequent sections)
Azure Kubernetes Service
Azure Kubernetes Service (AKS) makes it simple to deploy a managed Kubernetes cluster in Azure. It reduces the complexity and operational overhead of managing Kubernetes by offloading much of that responsibility to Azure. Here are examples of how you can setup an AKS cluster using Azure CLI, Azure portal or ARM template
Let's move on to the Kubernetes components now:
Please note that I am re-using part of the sections from the previous blog post (installation is the same after all!), but trying to keep it short at the same time to avoid repetition. For the parts that have been omitted e.g. explanation of the
Strimzicomponent spec for Kafka Connect etc., I would request you to check out that blog
Base install
To start off, we will install Strimzi and Kafka Connect, followed by the MongoDB connectors
Install Strimzi
Installing Strimzi using Helm is pretty easy:
//add helm chart repo for Strimzi
helm repo add strimzi https://strimzi.io/charts/
//install it! (I have used strimzi-kafka as the release name)
helm install strimzi-kafka strimzi/strimzi-kafka-operator
This will install the Strimzi Operator (which is nothing but a Deployment), Custom Resource Definitions and other Kubernetes components such as Cluster Roles, Cluster Role Bindings and Service Accounts
For more details, check out this link
To confirm that the Strimzi Operator had been deployed, check it's Pod (it should transition to Running status after a while)
kubectl get pods -l=name=strimzi-cluster-operator
NAME READY STATUS RESTARTS AGE
strimzi-cluster-operator-5c66f679d5-69rgk 1/1 Running 0 43s
Now that we have the "brain" (the Strimzi Operator) wired up, let's use it!
Kafka Connect
We will need to create some helper Kubernetes components before we deploy Kafka Connect.
Clone the GitHub repo
git clone https://github.com/abhirockzz/mongodb-kafkaconnect-kubernetes
cd mongodb-kafkaconnect-kubernetes
Kafka Connect will need to reference an existing Kafka cluster (which in this case is Azure Event Hubs). We can store the authentication info for the cluster as a Kubernetes Secret which can later be used in the Kafka Connect definition.
Update the eventhubs-secret.yaml file to include the credentials for Azure Event Hubs. Enter the connection string in the eventhubspassword attribute.
e.g.
apiVersion: v1
kind: Secret
metadata:
name: eventhubssecret
type: Opaque
stringData:
eventhubsuser: $ConnectionString
eventhubspassword: Endpoint=sb://<eventhubs-namespace>.servicebus.windows.net/;SharedAccessKeyName=RootManageSharedAccessKey;SharedAccessKey=<access-key>
Leave
eventhubsuser: $ConnectionStringunchanged
To create the Secret:
kubectl apply -f deploy/eventhubs-secret.yaml
Here is the Kafka Connect Strimzi definition:
apiVersion: kafka.strimzi.io/v1beta1
kind: KafkaConnect
metadata:
name: my-connect-cluster
annotations:
strimzi.io/use-connector-resources: "true"
spec:
image: abhirockzz/strimzi-kafkaconnect-mongodb:latest
version: 2.4.0
replicas: 1
bootstrapServers: [EVENT_HUBS_NAMESPACE.servicebus.windows.net]:9093
config:
group.id: strimzi-connect-cluster
offset.storage.topic: mongo-connect-cluster-offsets
config.storage.topic: mongo-connect-cluster-configs
status.storage.topic: mongo-connect-cluster-status
authentication:
type: plain
username: $ConnectionString
passwordSecret:
secretName: eventhubssecret
password: eventhubspassword
tls:
trustedCertificates: []
I have used a custom Docker image to package the MongoDB Kafka connector. It uses the Strimzi Kafka image as (strimzi/kafka) the base
image: abhirockzz/strimzi-kafkaconnect-mongodb:latest
For details, check out https://strimzi.io/docs/latest/#creating-new-image-from-base-str
Here is the Dockerfile - you can tweak it, use a different one, upload to any Docker registry and reference that in the Kafka Connect manifest
FROM strimzi/kafka:0.17.0-kafka-2.4.0
USER root:root
COPY ./connectors/ /opt/kafka/plugins/
USER 1001
We are almost ready to create a Kafka Connect instance. Before that, make sure that you update the bootstrapServers property with the one for Azure Event Hubs endpoint e.g.
spec:
version: 2.4.0
replicas: 1
bootstrapServers: <replace-with-eventhubs-namespace>.servicebus.windows.net:9093
To create the Kafka Connect instance:
kubectl apply -f deploy/kafka-connect.yaml
To confirm:
kubectl get kafkaconnects
NAME DESIRED REPLICAS
my-connect-cluster 1
This will create a Deployment and a corresponding Pod
kubectl get pod -l=strimzi.io/cluster=my-connect-cluster
NAME READY STATUS RESTARTS AGE
my-connect-cluster-connect-5bf9db5d9f-9ttg4 1/1 Running 0 1h
You have a Kafka Connect cluster in Kubernetes! Check out the logs using kubectl logs <pod name>
Check Azure Event Hubs - in the Azure Portal, open your Azure Event Hubs namespace and click on the Event Hubs tab, you should see Kafka Connect (internal) topics
{kind=link}
MongoDB Kafka Connectors
Source connector
We will now setup the source connector. Here is the definition:
apiVersion: kafka.strimzi.io/v1alpha1
kind: KafkaConnector
metadata:
name: mongodb-source-connector
labels:
strimzi.io/cluster: my-connect-cluster
spec:
class: com.mongodb.kafka.connect.MongoSourceConnector
tasksMax: 2
config:
connection.uri: [AZURE_COSMOSDB_CONNECTION_STRING]
topic.prefix: mongo
database: [MONGODB_DATABASE_NAME]
collection: [MONGODB_COLLECTION_NAME]
copy.existing: true
key.converter": org.apache.kafka.connect.json.JsonConverter
key.converter.schemas.enable: false
value.converter: org.apache.kafka.connect.json.JsonConverter
value.converter.schemas.enable: false
publish.full.document.only: true
pipeline: >
[{"$match":{"operationType":{"$in":["insert","update","replace"]}}},{"$project":{"_id":1,"fullDocument":1,"ns":1,"documentKey":1}}]
We use the label to refer to the kafka cluster we had just setup
metadata:
name: mongodb-source-connector
labels:
strimzi.io/cluster: my-connect-cluster
In the config section, we enter the connector config including the MongoDB connection string, database and collection names, whether we want to copy over existing data etc. The topic.prefix attribute is added to database & collection names to generate the name of the Kafka topic to publish data to. e.g. if the database and collection names are test_db, test_coll respectively, then the Kafka topic name will be mongo.test_db.test_coll. Also, the publish.full.document.only is set to true - this means that, only the document which has been affected (created, updated, replaced) will be published to Kafka, and not the entire change stream document (which contains a lot of other info)
For details, refer to the docs: https://docs.mongodb.com/kafka-connector/current/kafka-source/#source-connector-configuration-properties
In addition to this, I want to highlight the pipeline attribute:
pipeline: >
[{"$match":{"operationType":{"$in":["insert","update","replace"]}}},{"$project":{"_id":1,"fullDocument":1,"ns":1,"documentKey":1}}]
This is nothing but JSON (embedded within YAML.. what a joy!) which defines a custom pipeline. In case of the MongoDB API for Azure Cosmos DB, this is mandatory, due to the constraints in the Change Streams feature (at the time of writing). Please refer to this section in the [Azure Cosmos DB documentation] for details
Let's do one last thing before deploying the connector. To confirm that our setup for the source connector is indeed working, we will need to keep an eye on the Kafka topic in Event Hubs
Since we had specified
copy.existing: trueconfig for the connector, the existing items in the collection should be sent to the Kafka topic.
There are many ways you can do this. This document includes a lot of helpful links including, kafkacat, Kafka CLI etc.
I will be using
kafkacat
Install kafkacat - https://github.com/edenhill/kafkacat#install e.g. brew install kafkacat on mac. replace the properties in kafkacat.conf file (in the GitHub repo)
metadata.broker.list=[EVENTHUBS_NAMESPACE].servicebus.windows.net:9093
security.protocol=SASL_SSL
sasl.mechanisms=PLAIN
sasl.username=$ConnectionString
sasl.password=Endpoint=sb://[EVENTHUBS_NAMESPACE].servicebus.windows.net/;SharedAccessKeyName=RootManageSharedAccessKey;SharedAccessKey=[EVENTHUBS_ACCESS_KEY]
Export environment variables
export KAFKACAT_CONFIG=kafkacat.conf
export BROKER=[EVENTHUBS_NAMESPACE].servicebus.windows.net:9093
export TOPIC=[KAFKA_TOPIC e.g. mongo.test_db.test_coll]
The value for TOPIC follows a template, depending on the following connector config properties:
<topic.prefix>.<database>.<collection>
... and invoke kafkacat:
kafkacat -b $BROKER -t $TOPIC -o beginning
In the connector manifest file, update the Azure Cosmos DB connection string, name of MongoDB database as well as collection
e.g.
...
connection.uri: mongodb://<COSMOSDB_ACCOUNT_NAME>:<COSMOSDB_PRIMARY_KEY>@<COSMOSDB_ACCOUNT_NAME>.mongo.cosmos.azure.com:10255/?ssl=true&replicaSet=globaldb&maxIdleTimeMS=120000&appName=@<COSMOSDB_ACCOUNT_NAME>@
topic.prefix: mongo
database: my_source_db
collection: my_source_coll
...
Ok, you're all set. From a different terminal, deploy the connector
kubectl apply -f deploy/mongodb-source-connector.yaml
To confirm, simply list the connectors:
kubectl get kafkaconnectors
NAME AGE
mongodb-source-connector 70s
The connector should spin up and start weaving its magic. If you want to introspect the Kafka Connect logs:
kubectl logs -f $(kubectl get pod -l=strimzi.io/cluster=my-connect-cluster -o jsonpath='{.items[0].metadata.name}')
As per instructions, if you had created items in the source MongoDB collection, check the kafkacat terminal - you should see the Kafka topic records popping up. Go ahead and add a few more items to the MongoDB collection and confirm that you can see them in the kafkacat consumer terminal
Resume feature: the connector has the ability to continue processing from a specific point in time. As per connector docs - "The top-level _id field is used as the resume token which is used to start a change stream from a specific point in time."
Sink connector
We have the first half of the setup using which we can post MongoDB operations details to a Kafka topic. Let's finish the other half which will transform the data in the Kafka topic and store it in a destination MongoDB collection. For this, we will use the Sink connector - here is the definition
apiVersion: kafka.strimzi.io/v1alpha1
kind: KafkaConnector
metadata:
name: mongodb-sink-connector
labels:
strimzi.io/cluster: my-connect-cluster
spec:
class: com.mongodb.kafka.connect.MongoSinkConnector
tasksMax: 2
config:
topics: [EVENTHUBS_TOPIC_NAME]
connection.uri: [AZURE_COSMOSDB_CONNECTION_STRING]
database: [MONGODB_DATABASE_NAME]
collection: [MONGODB_COLLECTION_NAME]
post.processor.chain: com.mongodb.kafka.connect.sink.processor.DocumentIdAdder,com.mongodb.kafka.connect.sink.processor.KafkaMetaAdder
key.converter: org.apache.kafka.connect.json.JsonConverter
key.converter.schemas.enable: false
value.converter: org.apache.kafka.connect.json.JsonConverter
value.converter.schemas.enable: false
In the config section we need to specify the source Kafka topic (using topics) - this is the same Kafka topic to which the source connector has written the records to. database and collection should be populated with the names of the destination database and collection respectively. Note the post.processor.chain attribute contains com.mongodb.kafka.connect.sink.processor.KafkaMetaAdder - this automatically adds an attribute (topic-partition-offset) to the MongoDB document and captures the Kafka topic, partition and offset values
e.g. "topic-partition-offset" : "mongo.test_db1.test_coll1-0-74", where mongo.test_db1.test_coll1 is the topic name, 0 is the partition and 74 is the offset
Before creating the sink connector, update the manifest with MongoDB connection string, name of the source Kafka topic as well as the sink database and collection
e.g.
...
config:
topics: mongo.my_source_db.my_source_coll
connection.uri: mongodb://<COSMOSDB_ACCOUNT_NAME>:<COSMOSDB_PRIMARY_KEY>@<COSMOSDB_ACCOUNT_NAME>.mongo.cosmos.azure.com:10255/?ssl=true&replicaSet=globaldb&maxIdleTimeMS=120000&appName=@<COSMOSDB_ACCOUNT_NAME>@
database: my_sink_db
collection: my_sink_coll
...
You can now deploy the connector:
kubectl apply -f deploy/mongodb-sink-connector.yaml
To confirm, simply list the connectors:
kubectl get kafkaconnectors
NAME AGE
mongodb-source-connector 70s
mongodb-sink-connector 70s
To start with, the connector copies over existing records in the Kafka topic (if any) into the sink collection. If you had initially created items in source Azure Cosmos DB collection, they should have been copied over to Kafka topic (by the source connector) and subsequently persisted to the sink Azure Cosmos DB collection by the sink connector - to confirm this, query Azure Cosmos DB using any of the methods mentioned previously
Here is a sample record (notice the topic-partition-offset attribute)
{
"_id" : ObjectId("5eb937e5a68a237befb2bd44"),
"name" : "foo72",
"email" : "foo72@bar.com",
"status" : "online",
"topic-partition-offset" : "mongo.test_db1.test_coll1-0-74",
"CREATE_TIME" : 1589196724357
}
You can continue to experiment with the setup. Add, update and delete items in the source MongoDB collection and see the results...
Clean up
Once you are done exploring the application, you can delete the resources. If you placed Azure services (AKS, Event Hubs, Cosmos DB) under the same resource group, its easy executing a single command.
Please be aware that this will delete all the resources in the group which includes the ones you created as part of the tutorial as well as any other service instances you might have if you used an already existing resource group
az group delete --name $AZURE_RESOURCE_GROUP_NAME
Conclusion
As mentioned before, this was a simplified example to help focus on the different components and moving parts e.g. Kafka, Kubernetes, MongoDB, Kafka Connect etc. I demonstrated a use case where the record was modified before finally storing in the sink collection, but there are numerous other options which the connector offers, all of which are config based and do not require additional code (although the there are integration hooks as well). Some of the example include, using custom pipelines in the source connector, post-processors in the sink connector etc.
Resources
That's all for this blog. As always, stay tuned for more!
I'll leave you with a few resources:
- MongoDB Kafka Connector documentation - https://docs.mongodb.com/kafka-connector/current/
- MongoDB Kafka Connector GitHub repo - https://github.com/mongodb/mongo-kafka
- Strimzi documentation - https://strimzi.io/docs/latest/
- Kafka Connect - https://kafka.apache.org/documentation/#connect
Opinions expressed by DZone contributors are their own.
Comments