Feature Engineering
Feature engineering is a huge part of ML and deep learning. Read on to learn how feature engineering helps developers work with data.
Join the DZone community and get the full member experience.
Join For FreeData has become a first-class asset for modern businesses, corporations, and organizations irrespective of their size and scale. Any intelligent system, regardless of its complexity, needs to be powered by data. At the heart of any intelligent system, we have one or more data insight algorithms based on some sort of means of learning from data, such as machine learning, deep learning, or statistical methods, which consume this data to gather knowledge and provide intelligent insights over a period of time. Algorithms are pretty generic by themselves and cannot work out of the box on plain, raw data. There is a need to extract meaningful features from raw data so that it can be understood and consumed.
Any intelligent data insight system basically consists of an end-to-end pipeline, from ingesting raw data to leveraging data processing techniques to wrangle, process, and engineer meaningful features and attributes from this data. Then we usually leverage techniques like statistical models or machine learning models to model on these features and then deploy this model if necessary for future usage based on the problem to be solved at hand. A typical standard machine learning pipeline based on the Cross-industry standard process for a data mining industry standard process model is depicted below.
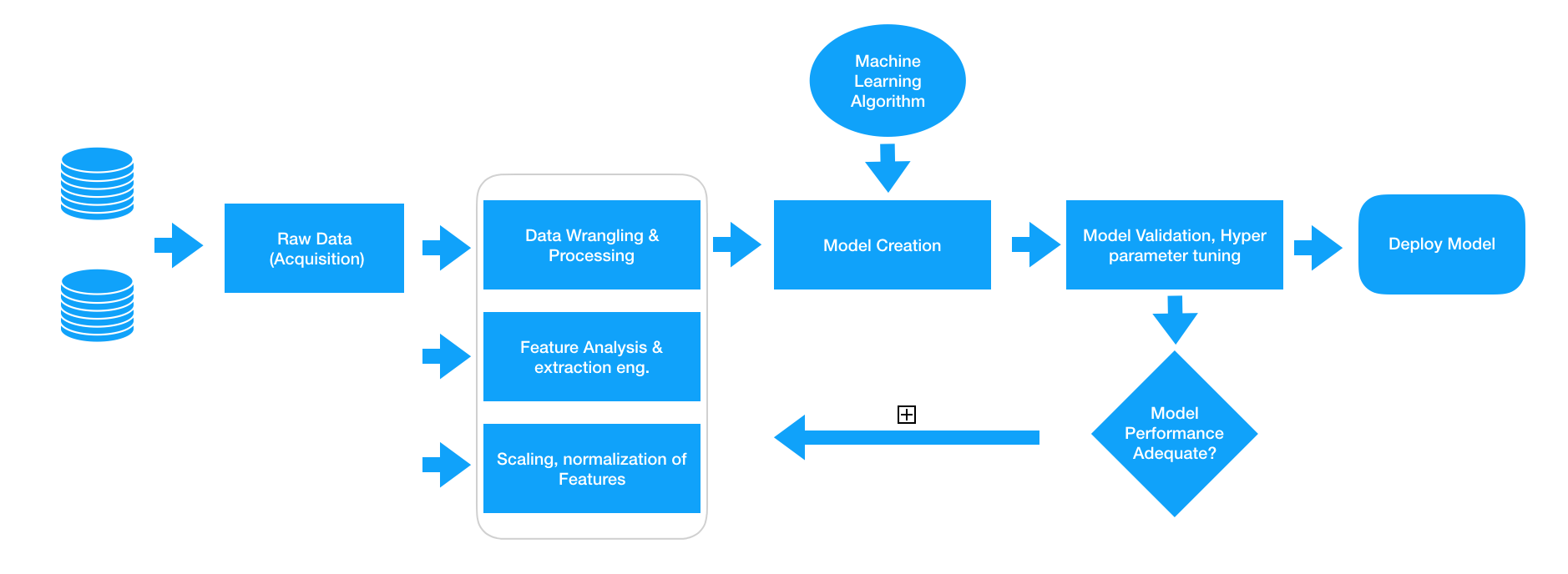
Ingesting raw data and building models on top of this data directly would be foolhardy since we wouldn’t get the desired results or performance and also algorithms themselves do not automatically extract meaningful features from plain raw data. The data preparation aspect pointed out in the figure above, where we deal with various methodologies to extract meaningful attributes or features from the raw data after it has gone through the necessary analysis of wrangling and pre-processing. Feature Engineering is an art as well as a science and this is the reason Data Scientists often spend 70% of their time in the data preparation phase before modeling.
“Feature engineering is the process of transforming raw data into features that better represent the underlying problem to the predictive models, resulting in improved model accuracy on unseen data.” - Dr. Jason Brownlee
This gives us some insight into why feature engineering is the process used for transforming data into features to act as inputs for machine learning models, namely that good quality features help in improving the overall model performance and accuracy. Features are also very much dependent on the underlying question. Thus, even though the machine learning task might be the same in different scenarios, like a classification of IoT events into normal and abnormal behavior or classifying customer sentiments, the features extracted in each scenario will be very different from each other.
What Are Features?
A feature is, typically, a specific representation on top of raw data, which is an individual, measurable attribute, typically depicted by a column in a dataset. Considering a generic two-dimensional dataset, each observation is depicted by a row and each feature by a column, which will have a specific value for an observation

Thus, like in the example in the figure above, each row typically indicates a feature vector and the entire set of features across all the observations forms a two-dimensional feature matrix, also known as a feature-set. This is akin to data frames or spreadsheets representing two-dimensional data. Typically machine learning algorithms work with these numeric matrices or tensors and hence most feature engineering techniques deal with converting raw data into some numeric representations which can be easily understood by these algorithms.
Features can be of two major types based on the dataset. Inherent raw features are obtained directly from the dataset with no extra data manipulation or engineering. Derived features are usually obtained from feature engineering, where we extract features from existing data attributes. A simple example would be creating a new feature “order fulfillment in days” from an orders dataset containing “order date” by just subtracting their order date from the current date. On the other hand, with deep learning, in particular, features are usually simple since the algorithms generate their own internal transformations. This approach requires large amounts of data and comes at the expense of interpretability. However, these trade-offs are often worthwhile in image processing or natural language processing use cases.
For most other use cases companies face, e.g. predictive analytics, feature engineering is necessary to convert data into a machine learning-ready format. The choice of features is crucial for both interpretability and performance. Without feature engineering, we wouldn’t have the accurate machine learning systems deployed by major companies today.
Feature Engineering
Numeric data typically represents data in the form of scalar values depicting observations, recordings or measurements. Here, by numeric data, we mean continuous data and not discrete data which is typically represented as categorical data. Numeric data can also be represented as a vector of values where each value or entity in the vector can represent a specific feature. Integers and floats are the most common and widely used numeric data types for continuous numeric data. Even though numeric data can be directly fed into machine learning models, you would still need to engineer features which are relevant to the scenario, problem, and domain before building a model. Hence the need for feature engineering still remains.
Opinions expressed by DZone contributors are their own.
Comments