Performance Optimization for Multi-Layered Cloud Native AWS Application
This article shares on-the-ground real Performance Optimization experience of multi-layered cloud-native AWS applications and provides prescriptive guidance.
Join the DZone community and get the full member experience.
Join For FreeCloud-native application development in AWS often requires complex, layered architecture with synchronous and asynchronous interactions between multiple components, e.g., API Gateway, Microservices, Serverless Functions, and system of record integration. Performance engineering requires analysis of the performance and resiliency of each component level and the interactions between these. While there is guidance available at the technical implementation of components, e.g., for AWS API Gateway, Lambda functions, etc., it still mandates understanding and applying end-to-end best practices for achieving the required performance requirements at the overall component architecture level. This article attempts to provide some fine-grained mechanisms to improve the performance of a complex cloud-native architecture flow curated from the on-ground experience and lessons learned from real projects deployed on production.
Problem Statement
The mission-critical applications often have stringent nonfunctional requirements for concurrency in the form of transactions per second (henceforth called “tps”). A proven mechanism to validate the concurrency requirement is to conduct performance testing.
Let’s look at the context of this article. The high-level cloud-native application architecture looks as follows:
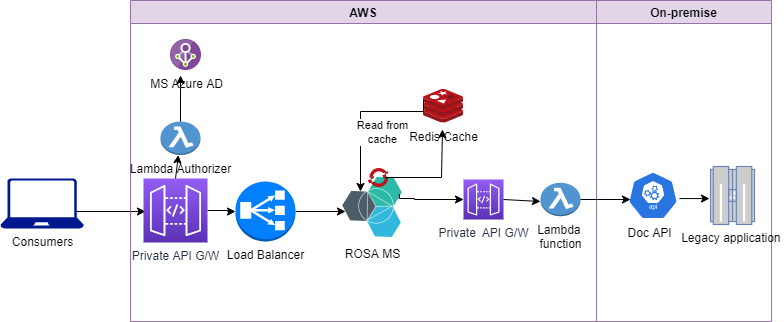
During performance testing, it was observed that the application client started getting errors, and the rate limit was exceeded after reaching transactions per second (tps).
Let’s say we have a default configuration in AWS API G/W with a daily quota of requests per day, whereas the request volumetric requirement is 22 million requests per day.
Performance Tuning Guidance To Address the Problem
There can be multiple root causes for this failure, as follows:
- Rate limiting in API G/W
- The issue in the Lambda function
- Backend application issue
While there can be multiple hotspots in the example architecture mentioned in the above section as follows, in this article, a pragmatic list of guidance and best practices are discussed that were learned from on-ground real project experience.
- Lambda Concurrency vs Throughput
- Concurrency Estimation
- Scaling Limits in Serverless
- Concurrency Controls
- Reserved Concurrency
- Provisioned Concurrency
- Managing Backpressure
- API Gateway Throttling
- Pool and share database connections
Failover Strategy
At this point, the client can queue the request and resubmit the failed requests in a way that is rate-limiting.

Optimizing Lambda Function
Since we started getting the 429 error, the rate limit was exceeded after reaching 130 tps. To add to the mystery, the requests that did manage to get through were experiencing agonizingly high latency. The system's responsiveness had taken a nosedive, and stakeholders were growing frustrated.
We decided to take a dive deep into Lambda functions' performance. In this paper, we will discuss what are the potential root cause of the performance issues in the Lambda function. One of the areas that we like to touch first will be the Cold start in the Lambda function. We learned that Cold starts could introduce unexpected delays, especially when Lambda functions weren't pre-warmed. Here, we decided to apply provisioned concurrency to alleviate the latency issue.
To diagnose the above throttling issue, we decided to analyze the concurrency limit of the Lambda functions set in our AWS account. The default concurrency limit for a new Lambda function is 1000 concurrent executions per region. If the number of incoming requests exceeds these limits, it can lead to throttling and rejected requests. Since the concurrency operates within a regional quota, which is shared among all functions in the same AWS Region, to guarantee that a function consistently maintains a specific concurrency level, it is suggested to configure it with reserved concurrency. When a function has reserved concurrency, no other function can utilize that allocated concurrency.
Furthermore, we uncovered another piece of the puzzle. The Lambda functions were making calls to external services that were taking an unexpectedly long time to respond. It seemed like these external services were dragging down their overall system performance.
To tackle this issue head-on, we decided to leverage AWS's Dead Letter Queue (DLQ) feature for the Lambda function. This feature would ensure that no important messages or events would be lost due to failures.
In addition, we also decided to increase the memory allocated to a Lambda function. AWS also proportionally increases CPU power and other resources. This action resulted in reduced execution time as the lambda function can process data faster (more CPU power) and execute code more quickly. Since AWS Lambda automatically scales the allocated CPU power in proportion to the memory, now the Lambda function can handle more simultaneous invocations.
With more memory, your function can perform tasks like caching data in memory, which can reduce the need for repeated data retrieval. Increasing memory also increases the cost of running your Lambda function. AWS charges you based on the memory size and the duration of execution. It's important to find the right balance between performance and cost for your specific use case.
Functions with more memory often experience shorter cold start times because AWS allocates more CPU power, allowing the function to initialize and execute your code more quickly.
Note:
- Increasing memory may not always result in linear performance improvements. Your function's performance could be limited by factors other than memory, such as database latency or network bottlenecks.
- It's essential to monitor and manage WS Lambda costs, especially when increasing memory. One should consider the trade-off between improved performance and increased cost to ensure your function remains cost-effective.
- When adjusting memory settings, it's advisable to perform testing and tuning to find the optimal configuration for your specific workload. This may involve experimenting with different memory sizes to achieve the desired balance between cost and performance.
In summary, increasing memory in AWS Lambda can significantly impact the performance and cost of your serverless functions. It's crucial to carefully consider your application's requirements and monitor the function's behavior to find the right memory allocation for your specific use case.
Optimizing Lambda Authorizer
The critical exam question for performance analysis in this context is: does all microservice in an orchestration need to be authorized through Lambda authorizer?
Not necessarily. The decision of whether to use a Lambda authorizer to authorize requests to a microservice in an orchestration depends on your security requirements and the specific design of your orchestration.
If the microservice is publicly exposed and requires authentication and authorization for every incoming request, then it might make sense to use a Lambda authorizer to handle the authentication and authorization logic for that microservice.
However, if the microservice is only accessible from within the orchestration, and the orchestration itself is already secured using some other mechanism, such as IAM roles and policies or VPC security groups, then using a Lambda authorizer for each microservice might be redundant and add unnecessary complexity.
It's important to keep in mind that using a Lambda authorizer for every microservice can add latency and cost to your orchestration, so it's important to weigh the benefits against the potential drawbacks before deciding whether to use a Lambda authorizer for each microservice.
There are several ways to reduce latency with a Lambda authorizer, which is used to authenticate and authorize incoming requests to your API Gateway.
- Use caching: Lambda authorizers can use caching to reduce the time it takes to authenticate and authorize requests. By caching previously authorized requests, subsequent requests can be served more quickly. You can configure the cache duration and size to optimize performance.
- Optimize your authorizer function code: Make sure your authorizer function code is optimized for performance. This includes minimizing the use of external dependencies, avoiding unnecessary operations, and optimizing resource usage.
- Use a VPC endpoint: If your authorizer function needs to access resources in a VPC, you can use a VPC endpoint to reduce latency. A VPC endpoint allows you to connect to AWS services over a private network, bypassing the public internet.
- Use a warm start strategy: Lambda functions have a cold start time, which can impact latency. To reduce cold start times, you can use a warm start strategy where you keep your authorizer function warm by periodically invoking it.
- Use a regional API endpoint: If you are using a regional API endpoint, ensure that your authorizer function is also deployed in the same region to minimize latency.
- Use a lightweight authorizer: If your authorization logic is simple, you can use a lightweight authorizer instead of a custom Lambda authorizer. A lightweight authorizer is a simpler way to authorize requests, and it can be faster than a custom Lambda authorizer.
Optimizing API Gateway
Amazon API Gateway provides four basic types of throttling-related settings:
- AWS throttling limits are applied across all accounts and clients in a region.
- Per-account limits are applied to all APIs in an account in a specified Region
- Per API, per-stage throttling limits are applied at the API method level for a stage.
- Per-client throttling limits are applied to clients that use API keys associated with your usage plan as client identifiers.
If the throttling settings in API Gateway exceed the set limits, it can lead to 429 errors. To resolve this,
- Review and adjust the throttling settings in your API Gateway stage.
- Consider using API keys or usage plans to manage and control usage.
AWS API Gateway Cache
AWS API Gateway Cache involves using ElastiCache for Redis to create a distributed caching solution that improves API performance, reduces latency, and lowers the load on backend servers.
API Gateway Cache creates a distributed cache cluster using Amazon ElastiCache for Redis. The cache cluster provides a highly available and scalable caching solution that can be used across multiple regions.
- Cache Keys: API Gateway Cache uses cache keys to identify and retrieve cached responses. Cache keys are created based on the request parameters of the API request. The cache keys are generated using the request method, URI, headers, and query parameters.
- Cache TTL: The time-to-live (TTL) value determines the duration for which the response will be cached. API Gateway Cache allows you to set the TTL value for each API request. Once the TTL expires, the cached response is deleted from the cache.
- Cache Invalidation: API Gateway Cache supports cache invalidation, which allows you to delete cached responses before the TTL expires. You can invalidate cached responses using the AWS Management Console, AWS CLI, or AWS SDK.
- Cache-Control: API Gateway Cache allows you to control the cache behavior using cache control headers. You can set cache control headers in the API response to control caching behavior for individual API requests.
- Cache Metrics: API Gateway Cache provides metrics to monitor cache usage, hit rate, and latency. You can use CloudWatch to monitor cache metrics and trigger alarms based on thresholds.
Throttling can be applied in three different ways in API G/W.
- Account Level
- API Level
- Method Level
Opinions expressed by DZone contributors are their own.
Comments