Storage Systems For Real-Time Personalized Recommendations
Recommendation systems personalize content with machine learning, boosting engagement. They need fast, scalable storage to handle big, changing datasets.
Join the DZone community and get the full member experience.
Join For FreeRecommendation systems and content discovery are becoming ubiquitous in the era of artificial intelligence and machine learning. When you listen to music on Spotify, it's likely you’ve been suggested a song or podcast based on your listening history, playlists created by other users, and even the time of day. Similarly, when you watch YouTube, you’ve likely seen recommendations for videos, and channels based on your tailored preferences, whether it is content you’ve liked or disliked or your video-watching habits like pausing, replaying, and skipping. These are just two examples, but recommendations are ubiquitous, ranging from your popular e-commerce platform, or retailer’s website to the content you engage in, whether that's news, videos, social media feeds, or posts. Machine learning and predictive analytics enable these products to provide a superior user experience.
What Are Personalized Recommendations?
In the past, when machine learning and predictive analytics weren’t as accessible, several applications leveraged human-curated recommendations. While this enabled some curation and discovery, the experience wasn’t very tailored to individuals. With the democratization of machine learning and predictive analytics and the popularization of large-scale social media (for example, Facebook's news feed to Tiktok's ‘For You’ pages), personalized recommendations have become mainstream. A personalized approach allows the provider to tailor the experience with the help of a vast array of data points.
A personalized experience has been pivotal in making content discovery an effortless and enjoyable part of the experience. The business case is straightforward: investments in ideal personalization experiences lead to an uplift in digital conversions like conversion rates, click-through rates, or increased revenue. In some cases, this can also be the increased user’s watch time or engagement metric, so the user not only spends more time but also returns more often, improving retention metrics. The metric that the business is looking to move, informs the technology choices, where the machine learning models are optimized for the specific output metrics.
What Data Is Needed to Power Recommendation Models?
Typically, a recommendation system brings in two kinds of data: (a) the product or content inventory and (b) user preferences and behaviors.
- The product or content inventory, in the case of YouTube, would be the videos, documentaries, and all available titles to watch; while for a website like Temu or Etsy would be the products it is selling. For this reason, this is largely unchanged data, where storage systems don't need to be evolving at a rapid pace. When inventory updates, these databases can be updated through batch updates. The product data can range from typical titles and quantities to more detailed metadata like descriptions, images, genres, or even SKU details.
- The user behavior or preferences, in their simplest forms, can be how the users engage with the services: so log data, and events from web analytics are typical starting points. This can be further evolved by maintaining user profiles and personas to build audience types for recommendation systems. More complex neural networks don’t rely on static audience types, and model user behavior into the model, where user feedback informs the model, if the user clicked on a specific recommendation or disregarded it.
Storage for Real-Time Recommendation Models
The data used in real-time recommendation systems is often large-scale, generated quickly, and diverse in format:
- Volume: Large-scale user data, in the order of terabytes or petabytes.
- Velocity: Data is quickly generated from user interactions.
- Variety: Combination of structured, semi-structured, and unstructured data.
Challenges of Real-Time Data Storage
The requirements of real-time recommendations pose challenges for traditional storage systems:
- Low latency: Systems need to ingest, process, and retrieve data with minimal delays to ensure recommendations are responsive to changing user behavior.
- Scalability: The ability to handle sudden bursts of activity and accommodate growing datasets is crucial.
- Data freshness: Recommendation models require the most up-to-date data to remain accurate and relevant.
- Data consistency: Real-time updates must be consistently reflected across distributed systems to avoid serving outdated recommendations.
Storage System Technologies
Diverse storage systems power the demands of real-time recommendations:
- In-memory databases: Systems like Redis and Memcached provide lightning-fast read/write speeds for storing frequently used data such as user profiles and recent activity.
- NoSQL databases: Document-oriented databases (e.g., MongoDB, Google Cloud Firestore) and columnar databases (e.g., Cassandra, Google Bigtable) offer flexibility and scalability for managing vast and varied datasets.
- Streaming platforms: Platforms like Apache Kafka, Google Cloud Pub/Sub, and Amazon Kinesis handle and process continuous streams of real-time user interaction data.
- Search engines: Systems like Elasticsearch and Google Cloud Search facilitate lightning-fast searches over massive datasets, enabling complex querying for item and content recommendations.
Hybrid Architectures
Real-time recommendation systems often adopt a hybrid architecture, strategically combining technologies for optimal performance:
- In-memory databases for serving real-time recommendations with ultra-low latency.
- NoSQL databases for storing larger historical and contextual data.
- Streaming platforms for processing real-time interaction data and event-driven updates.
Data Architecture for Real-Time Recommendations
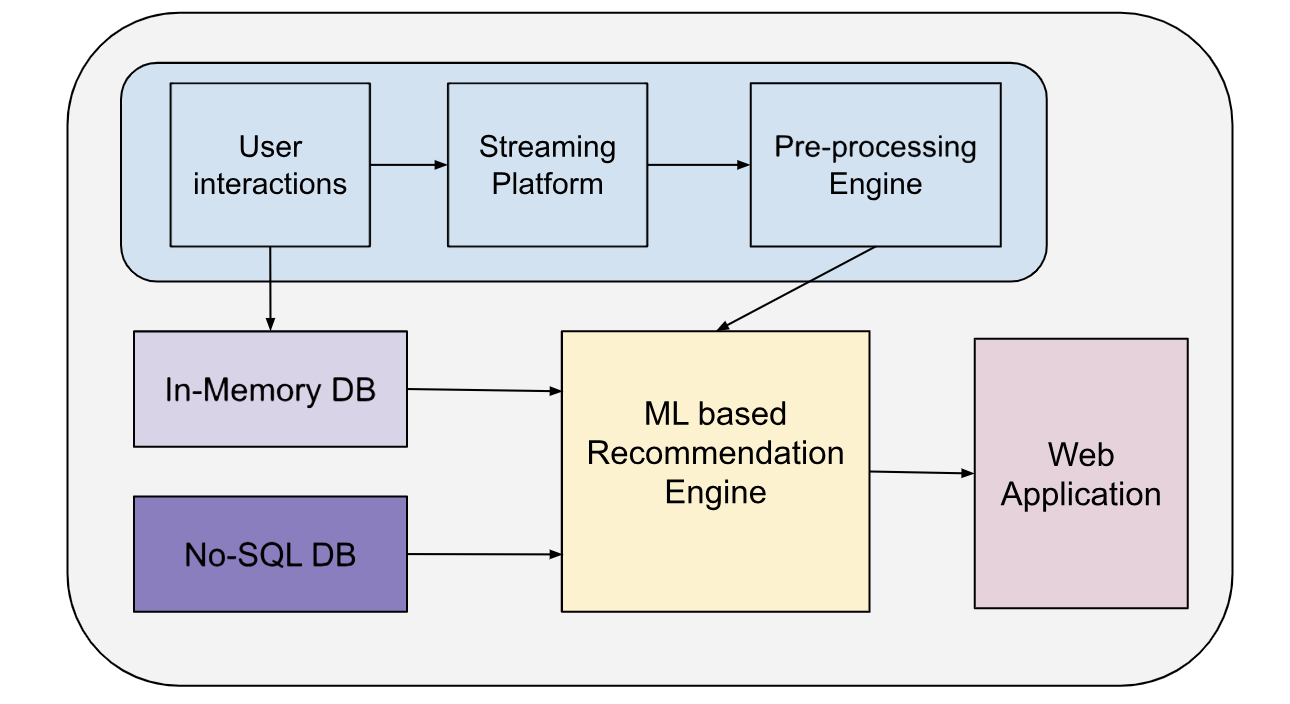
- User interactions: Represents the actions users take.
- Streaming platform: Processes real-time data streams.
- Pre-processing: Prepares data for the recommendation model.
- In-memory database: Caches user profiles, preferences, and recent activity for fast access.
- NoSQL database: Stores larger datasets, historical information, and product/content details.
- Recommendation engine: The core machine learning component that generates recommendations.
- Web application: Delivers recommendations to the user.
Additional Considerations
- Data caching: Layering caching solutions (e.g., CDN, browser-side) reduces load on the primary storage systems and improves responsiveness.
- Data governance and privacy: Implementing robust practices to ensure data security, ethical use, and compliance with regulations (e.g., GDPR).
Conclusion
The choice of the right data infrastructure is crucial for the success of real-time recommendation systems. The unique challenges posed by large-scale, high-velocity, and diverse data require a thoughtful combination of technologies. As recommendation systems become more sophisticated, the demands of the underlying data infrastructure will similarly advance. The field will continue to evolve, potentially incorporating technologies optimized for even more complex and responsive AI-powered recommendations.
Opinions expressed by DZone contributors are their own.
Comments