Steps To Industry-Leading Query Speed: Evolution of the Apache Doris Execution Engine
From the Volcano Model to the Pipeline Execution Engine, and now PipelineX, Apache Doris brings its computation efficiency to a higher level with each iteration.
Join the DZone community and get the full member experience.
Join For FreeWhat makes a modern database system? The three key modules are query optimizer, execution engine, and storage engine. Among them, the role of execution engine to the DBMS is like the chef to a restaurant. This article focuses on the execution engine of the Apache Doris data warehouse, explaining the secret to its high performance.
To illustrate the role of the execution engine, let's follow the execution process of an SQL statement:
- Upon receiving an SQL query, the query optimizer performs syntax/lexical analysis and generates the optimal execution plan based on the cost model and optimization rules.
- The execution engine then schedules the plan to the nodes, which operate on data in the underlying storage engine and then return the query results.
The execution engine performs operations like data reading, filtering, sorting, and aggregation. The efficiency of these steps determines query performance and resource utilization. That's why different execution models bring distinction in query efficiency.
Volcano Model
The Volcano Model (originally known as the Iterator Model) predominates in analytical databases, followed by the Materialization Model and Vectorized Model. In a Volcano Model, each operation is abstracted as an operator, so the entire SQL query is an operator tree. During query execution, the tree is traversed top-down by calling the next()interface, and data is pulled and processed from the bottom up. This is called a pull-based execution model.
The Volcano Model is flexible, scalable, and easy to implement and optimize. It underpins Apache Doris before version 2.1.0. When a user initiates an SQL query, Doris parses the query, generates a distributed execution plan, and dispatches tasks to the nodes for execution. Each individual task is an instance. Take a simple query as an example:
select age, sex from employees where age > 30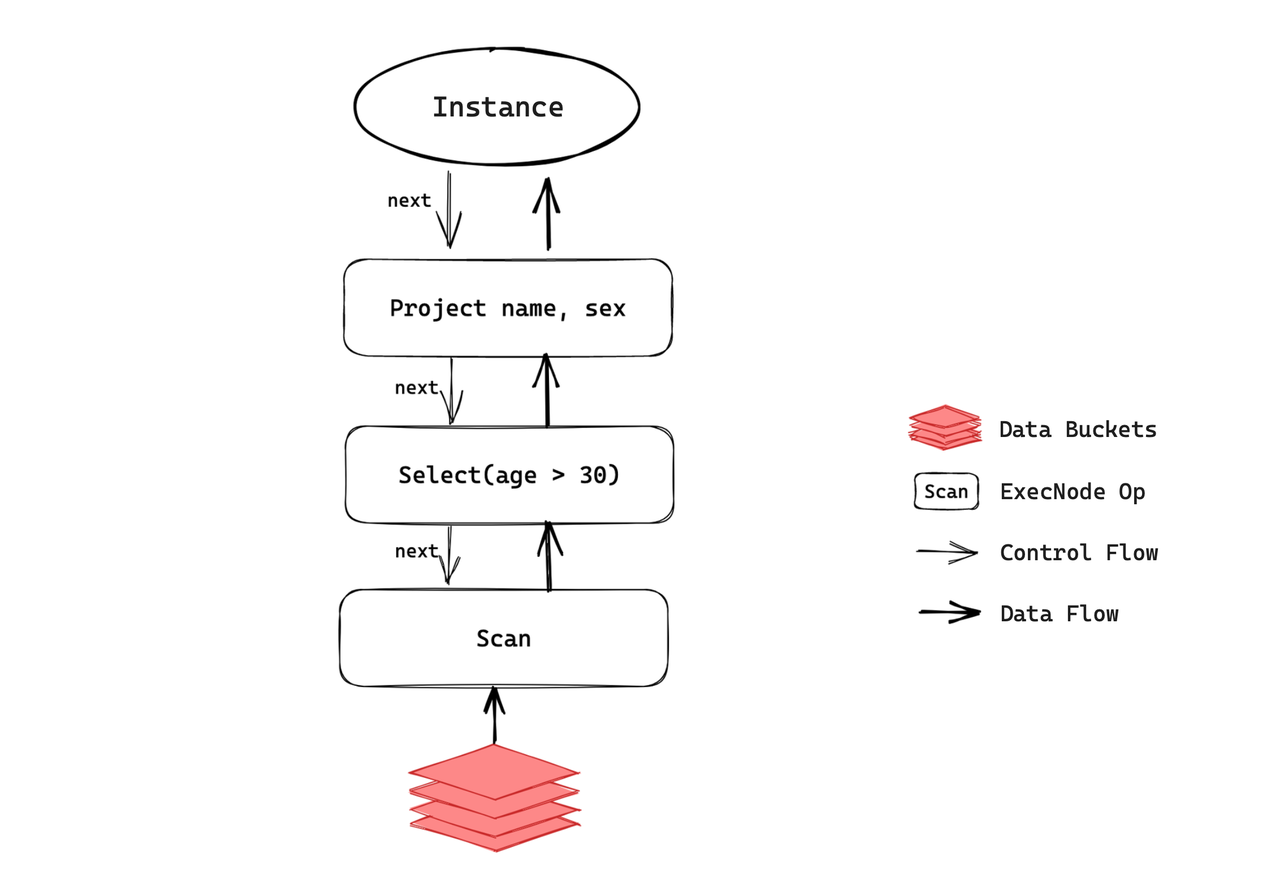
In an instance, data flows between operators are propelled by the next() method. If the next() method of an operator is called, it will first call the next() of its child operator, obtain data from it, and then process the data to produce output.
next() is a synchronous method. In other words, the current operator will be blocked if its child operator does not provide data for it. In this case, the next() method of the root operator needs to be called in a loop until all data is processed, which is when the instance finishes its computation.
Such execution mechanism faces a few bottlenecks in single-node, multi-core use cases:
- Thread blocking: In a fixed-size thread pool if an instance occupies a thread and it is blocked, that will easily cause a deadlock when there are a large number of instances requesting execution simultaneously. This is especially the case when the current instance is dependent on other instances. Additionally, if a node is running more instances than the number of CPU cores it has, the system scheduling mechanism will be heavily relied upon and a huge context-switching overhead can be produced. In a colocation scenario, this will lead to an even larger thread-switching overhead.
- CPU contention: The threads might compete for CPU resources so queries of different sizes and between different tenants might interfere with each other.
- Underutilization of the multi-core computing capabilities: Execution concurrency relies heavily on data distribution. Specifically, the number of instances running on a node is limited by the number of data buckets on that node. In this case, it's important to set an appropriate number of buckets. If you shard the data into too many buckets, that will become a burden for the system and bring unnecessary overheads; if the buckets are too few, you will not be able to utilize your CPU cores to the fullest. However, in a production environment, it is not always easy to estimate the proper number of buckets you need, thus performance loss.
Pipeline Execution Engine
Based on the known issues of the Volcano Model, we've replaced it with the Pipeline Execution Engine since Apache Doris 2.0.0.
As the name suggests, the Pipeline Execution Engine breaks down the execution plan into pipeline tasks and schedules these pipeline tasks into a thread pool in a time-sharing manner. If a pipeline task is blocked, it will be put on hold to release the thread it is occupying. Meanwhile, it supports various scheduling strategies, meaning that you can allocate CPU resources to different queries and tenants more flexibly.
Additionally, the Pipeline Execution Engine pools together data within data buckets, so the number of running instances is no longer capped by the number of buckets. This not only enhances Apache Doris' utilization of multi-core systems but also improves system performance and stability by avoiding frequent thread creation and deletion.
Example
This is the execution plan of a join query. It includes two instances:
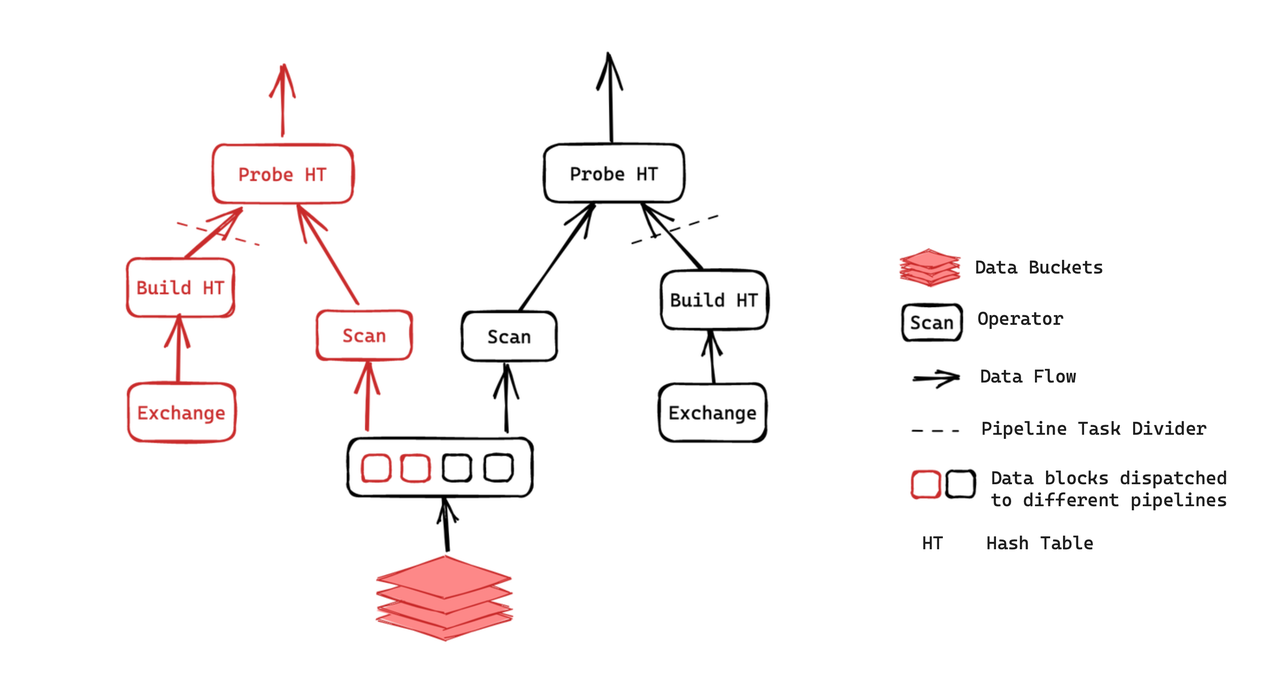
As illustrated, the Probe operation can only be executed after the hash table is built, while the Build operation is reliant on the computation results of the Exchange operator. Each of the two instances is divided into two pipeline tasks as such. Then these tasks will be scheduled in the "ready" queue of the thread pool. Following the specified strategies, the threads obtain the tasks to process. In a pipeline task, after one data block is finished, if the relevant data is ready and its runtime stays within the maximum allowed duration, the thread will continue to compute the next data block.
Design and Implementation
Avoid Thread Blocking
As mentioned earlier, the Volcano Model is faced with a few bottlenecks:
- If too many threads are blocked, the thread pool will be saturated and unable to respond to subsequent queries.
- Thread scheduling is entirely managed by the operating system, without any user-level control or customization.
How does the Pipeline Execution Engine avoid such issues?
- We fix the size of the thread pool to match the CPU core count. Then we split all operators that are prone to blocking into pipeline tasks. For example, we use individual threads for disk I/O operations and RPC operations.
- We design a user-space polling scheduler. It continuously checks the state of all executable pipeline tasks and assigns executable tasks to threads. With this in place, the operating system doesn't have to frequently switch threads, thus less overheads. It also allows customized scheduling strategies, such as assigning priorities to tasks.
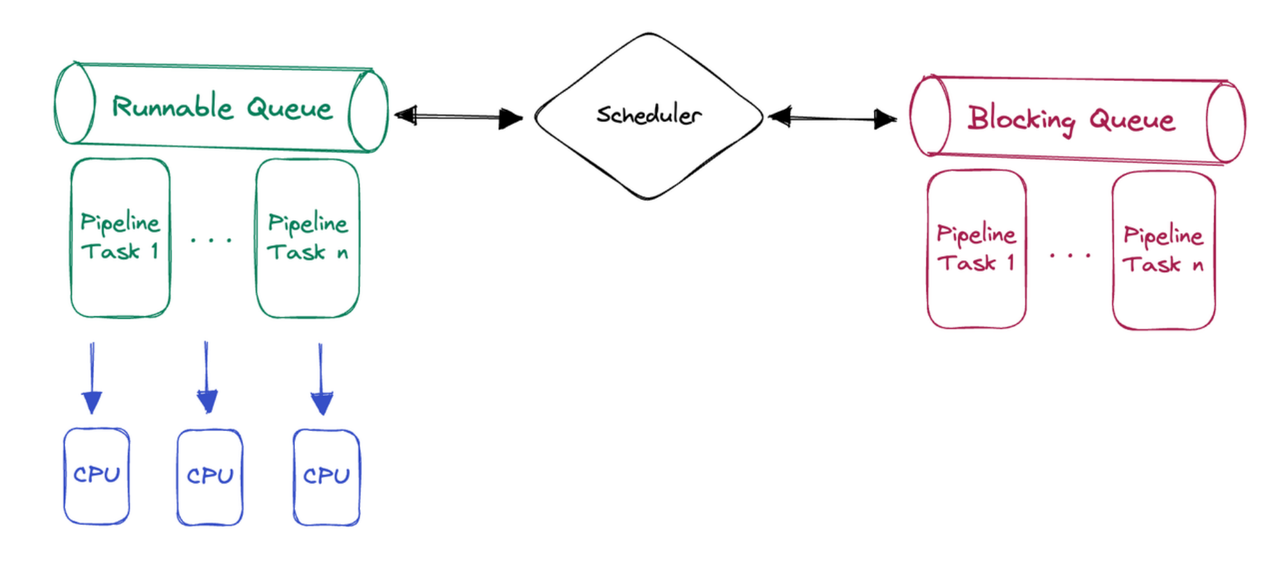
Parallelization
Before version 2.0, Apache Doris requires users to set a concurrency parameter for the execution engine (parallel_fragment_exec_instance_num), which does not dynamically change based on the workloads. Therefore, it is a burden for users to figure out an appropriate concurrency level that leads to optimal performance.
What's the industry's solution to this?
Presto's idea is to shuffle the data into a reasonable number of partitions during execution, which requires minimal concurrency control from users. On the other hand, DuckDB introduces an extra synchronization mechanism instead of shuffling. We decide to follow Presto's track of Presto because the DuckDB solution inevitably involves the use of locks, which works against our purpose of avoiding blocking.
Unlike Presto, Apache Doris doesn't need an extra Local Exchange mechanism to shards the data into an appropriate number of partitions. With its massively parallel processing (MPP) architecture, Doris already does so during shuffling. (In Presto's case, it re-partitions the data via Local Exchange for higher execution concurrency. For example, in hash aggregation, Doris further shards the data based on the aggregation key in order to fully utilize the CPU cores. Also, this can downsize the hash table that each execution thread has to build.)
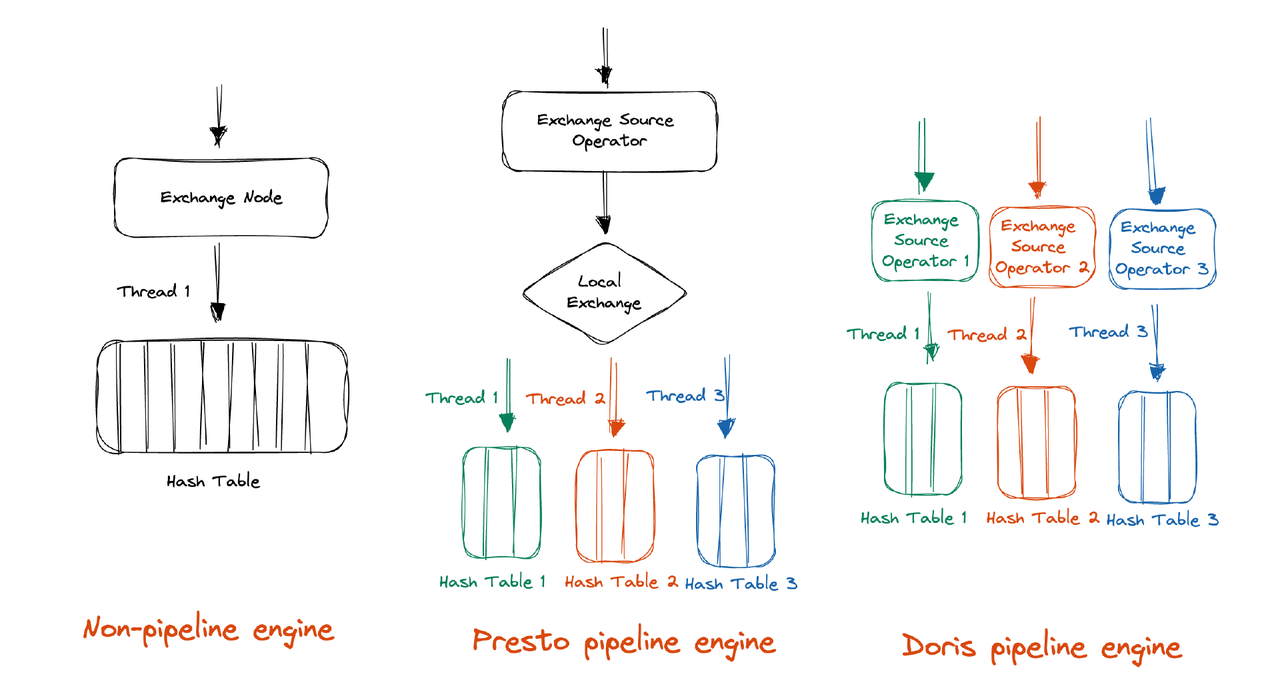
Based on the MPP architecture, we only need two improvements before we achieve what we want in Doris:
- Increase the concurrency level during shuffling. For this, we only need to have the frontend (FE) perceive the backend (BE) environment and then set a reasonable number of partitions.
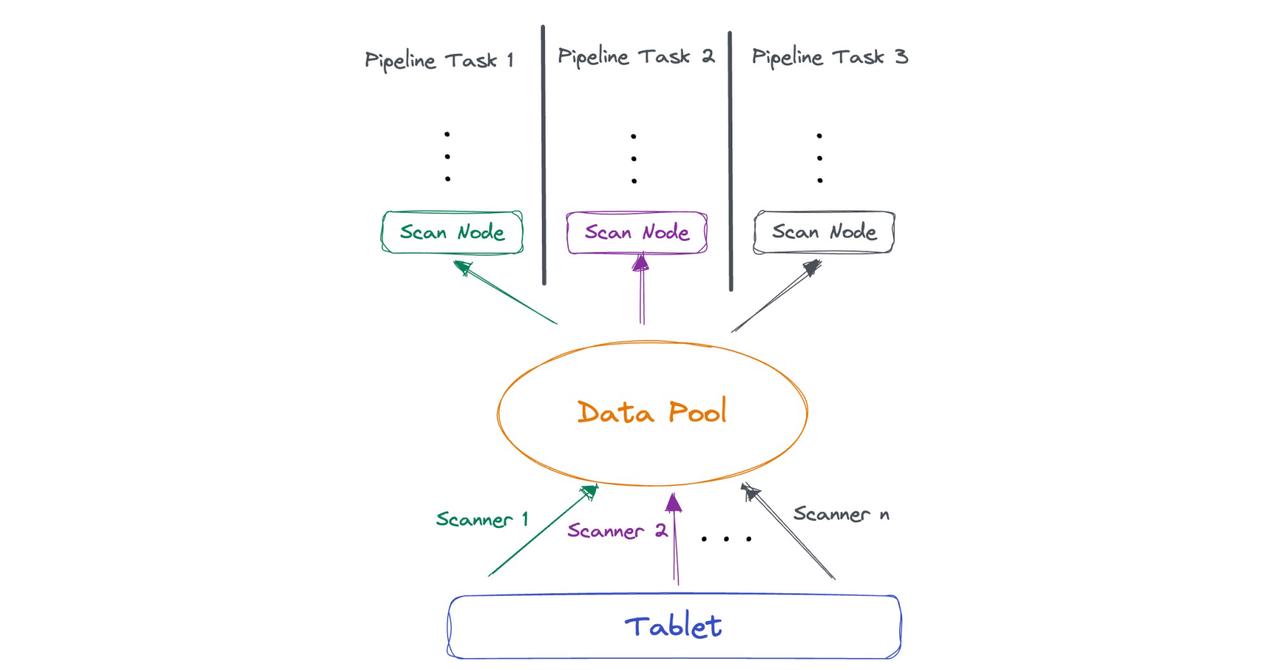
- Implement concurrent execution after data reading by the scan layer. To do this, we need a logical restructuring of the scan layer to decouple the threads from the number of data tablets. This is a pooling process. We pool the data read by scanner threads, so it can be fetched by multiple pipeline tasks directly.
PipelineX
Introduced in Apache Doris 2.0.0, the pipeline execution engine has been improving query performance and stability under hybrid workload scenarios (queries of different sizes and from different tenants). In version 2.1.0, we've tackled the known issues and upgraded this from an experimental feature to a robust and reliable solution, which is what we call PipelineX.
PipelineX has provided answers to the following issues that used to challenge the Pipeline Execution Engine:
- Limited execution concurrency
- High execution overhead
- High scheduling overhead
- Poor readability of operator profile
Execution Concurrency
The Pipeline Execution Engine remains under the restriction of the static concurrency parameter at FE and the tablet count at the storage layer, making itself unable to capitalize on the full computing resources. Plus, it is easily affected by data skew.
For example, suppose that Table A contains 100 million rows but it has only 1 tablet, which means it is not sharded enough, let's see what can happen when you perform an aggregation query on it:
SELECT COUNT(*) FROM A GROUP BY A.COL_1;During query execution, the query plan is divided into two fragments. Each fragment, consisting of multiple operators, is dispatched by frontend (FE) to backend (BE). The BE starts threads to execute the fragments concurrently.
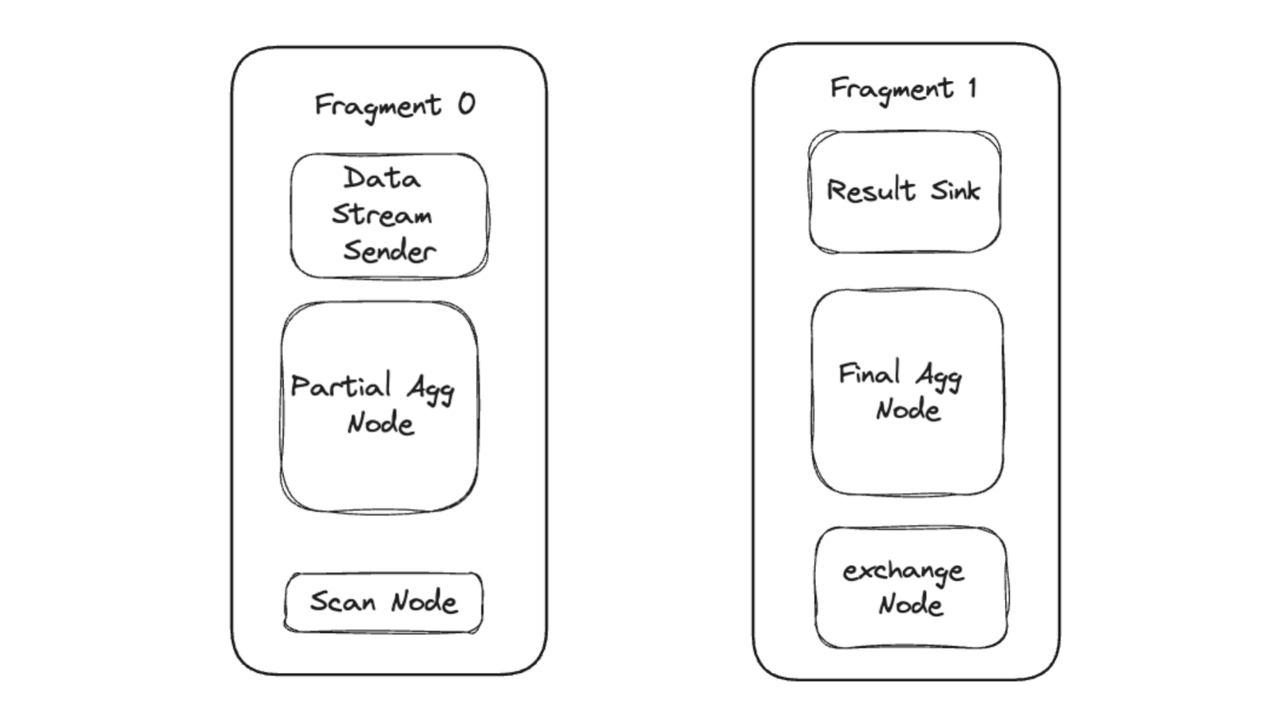
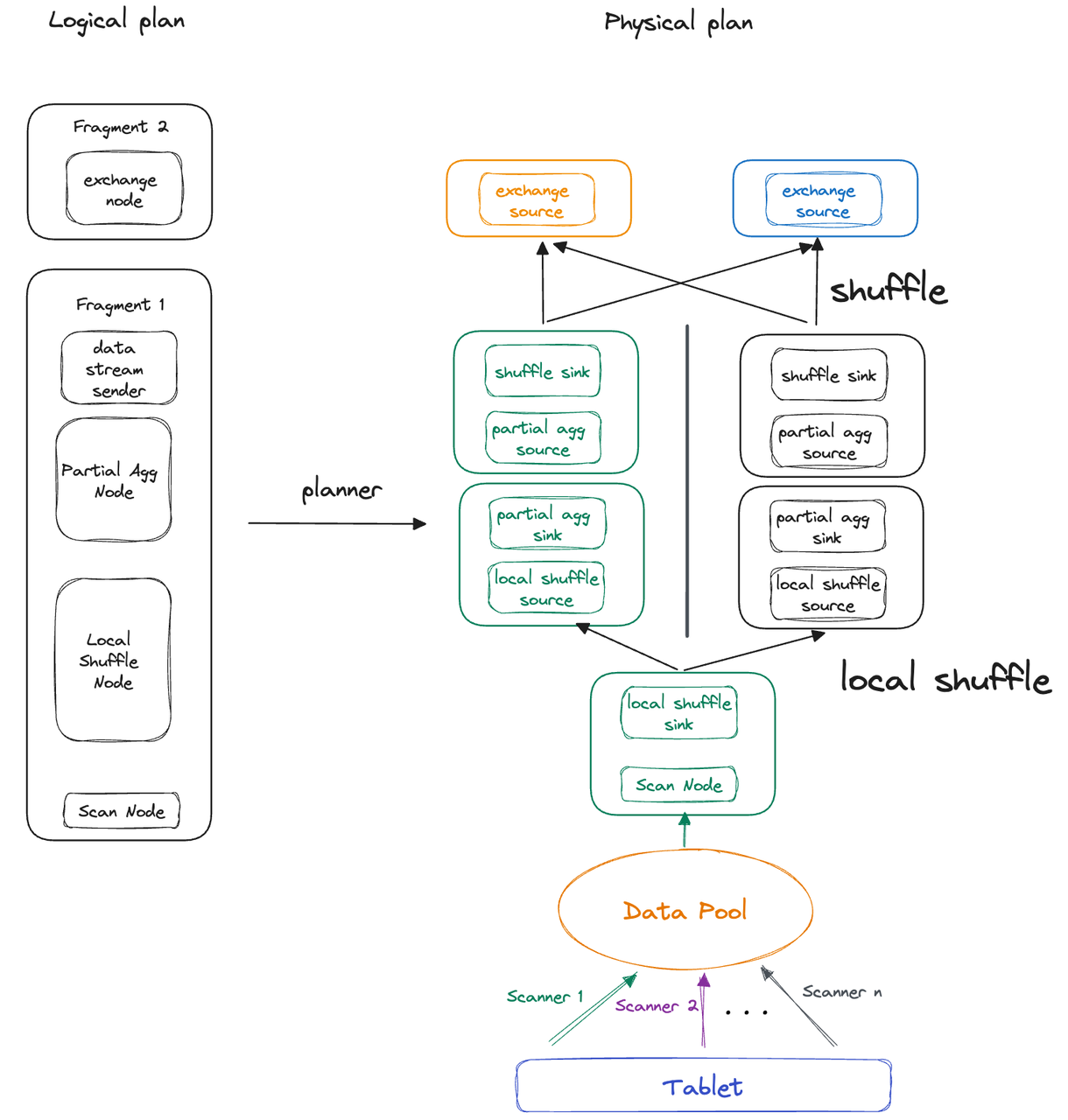
Now, let's focus on Fragment 0 for further elaboration. Because there is only one tablet, Fragment 0 can only be executed by one thread. That means aggregation of 100 million rows by one single thread. If you have 16 CPU cores, ideally, the system can allocate 8 threads to execute Fragment 0. In this case, there is a concurrency disparity of 8 to 1. This is how the number of tablets restricts execution concurrency and also why we introduce the idea of Local Shuffle mechanism to remove that restriction in Apache Doris 2.1.0. So this is how it works in PipelineX:
- The threads execute their own pipeline tasks, but the pipeline tasks only maintain their runtime state (known as Local State), while the information that shared across all pipeline tasks (known as Global State) is managed by one pipeline object.
- On a single BE, the Local Shuffle mechanism is responsible for data distribution and data balancing across pipeline tasks.
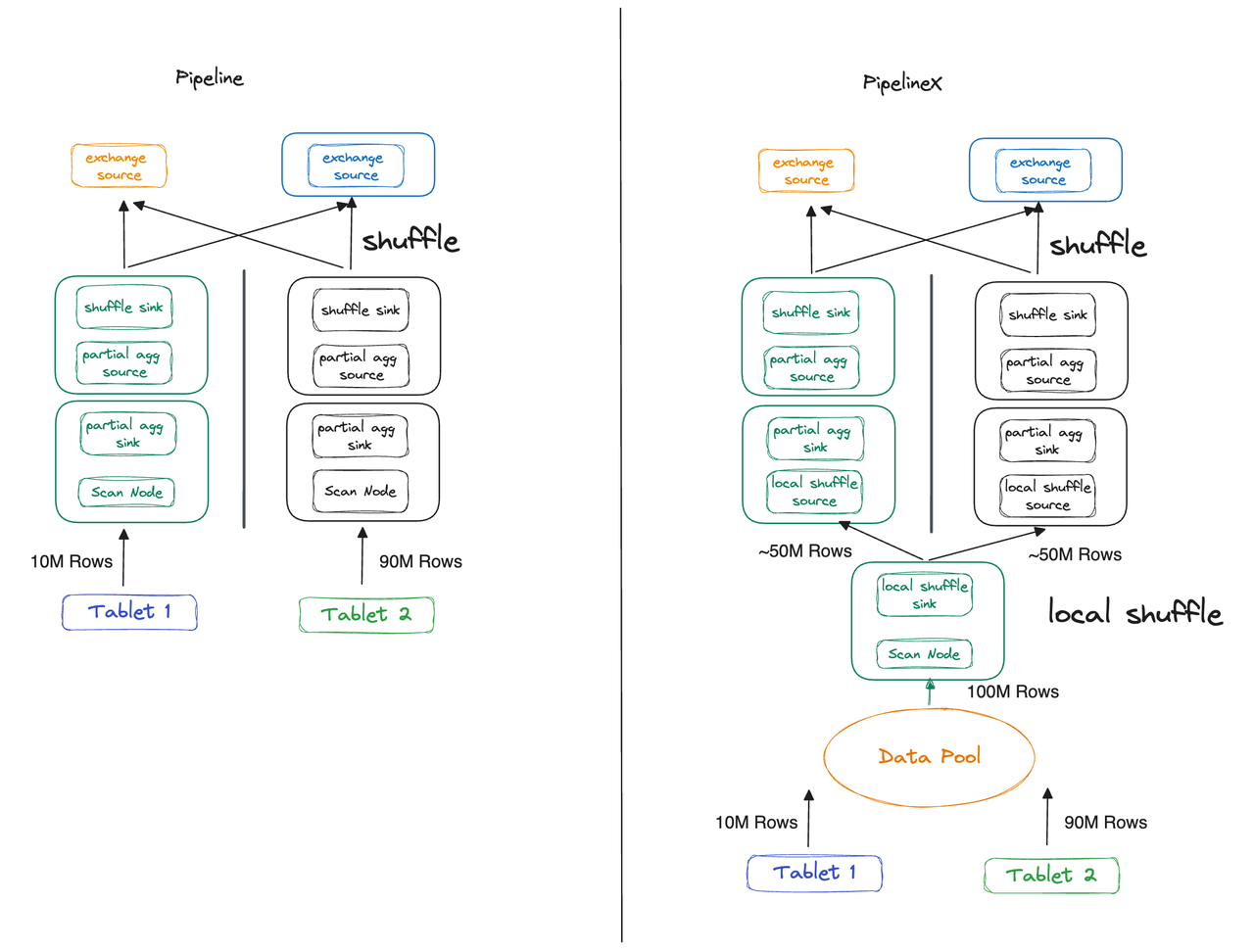
Apart from decoupling execution concurrency from tablet count, Local Shuffle can avoid performance loss due to data skew. Again, we will explain with the foregoing example.
This time, we shard Table A into two tablets instead of one, but the data is not evenly distributed. Tablet 1 and Tablet 3 hold 10 million and 90 million rows, respectively. The Pipeline Execution Engine and PipelineX Execution Engine respond differently to such data skew:
- Pipeline Execution Engine: Thread 1 and Thread 2 executes Fragment 1 concurrently. The latter takes 9 times as long as Thread 1 because of the different data sizes they deal with.
- PipelineX Execution Engine: With Local Shuffle, data is distributed evenly to the two threads, so they take almost equal time to finish.
Execution Overhead
Under the Pipeline Execution Engine, because the expressions of different instances are individual, each instance is initialized individually. However, since the initialization parameters of instances share a lot in common, we can reuse the shared states to reduce execution overheads. This is what PipelineX does: it initializes the Global State at a time, and the Local State sequentially.
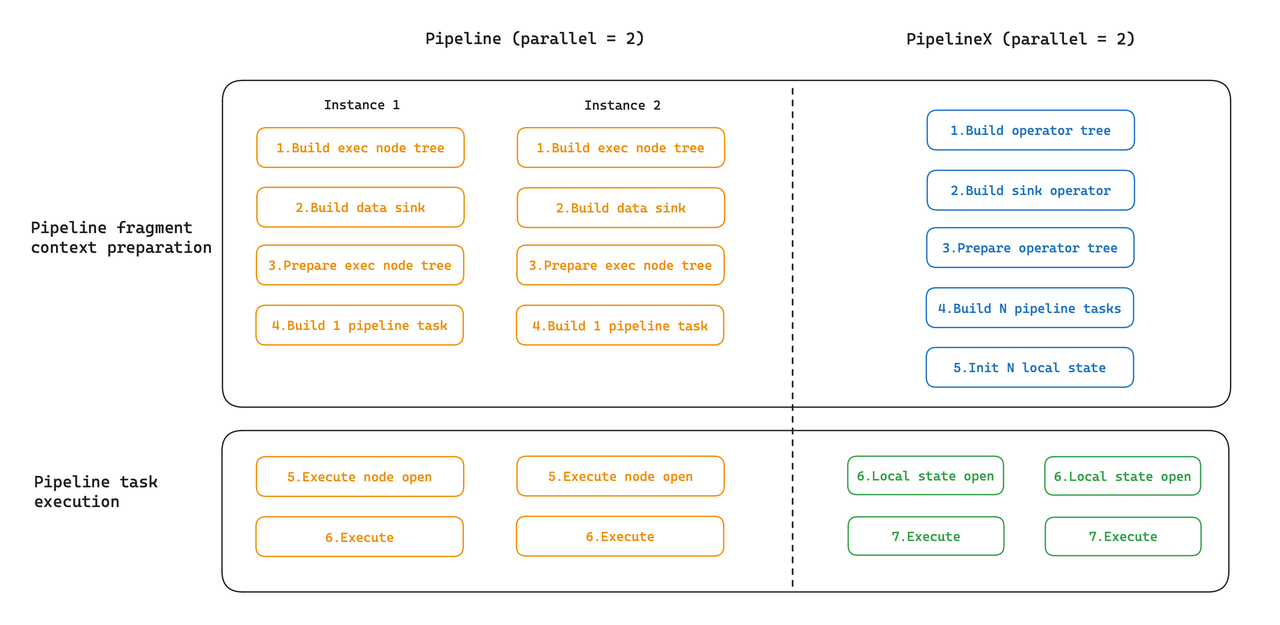
Scheduling Overhead
In the Pipeline Execution Engine, the blocked tasks are put into a blocked queue, where a dedicated thread takes polls and moves the executable tasks over to the runnable queue. This dedicated scheduling thread consumes a CPU core and incurs overheads that can be particularly noticeable on systems with limited computing resources.
As a better solution, PipelineX encapsulates the blocking conditions as dependencies, and the task status (blocked or runnable) will be triggered to change by event notifications. Specifically, when RPC data arrives, the relevant task will be considered as ready by the ExchangeSourceOperator and then moved to the runnable queue.
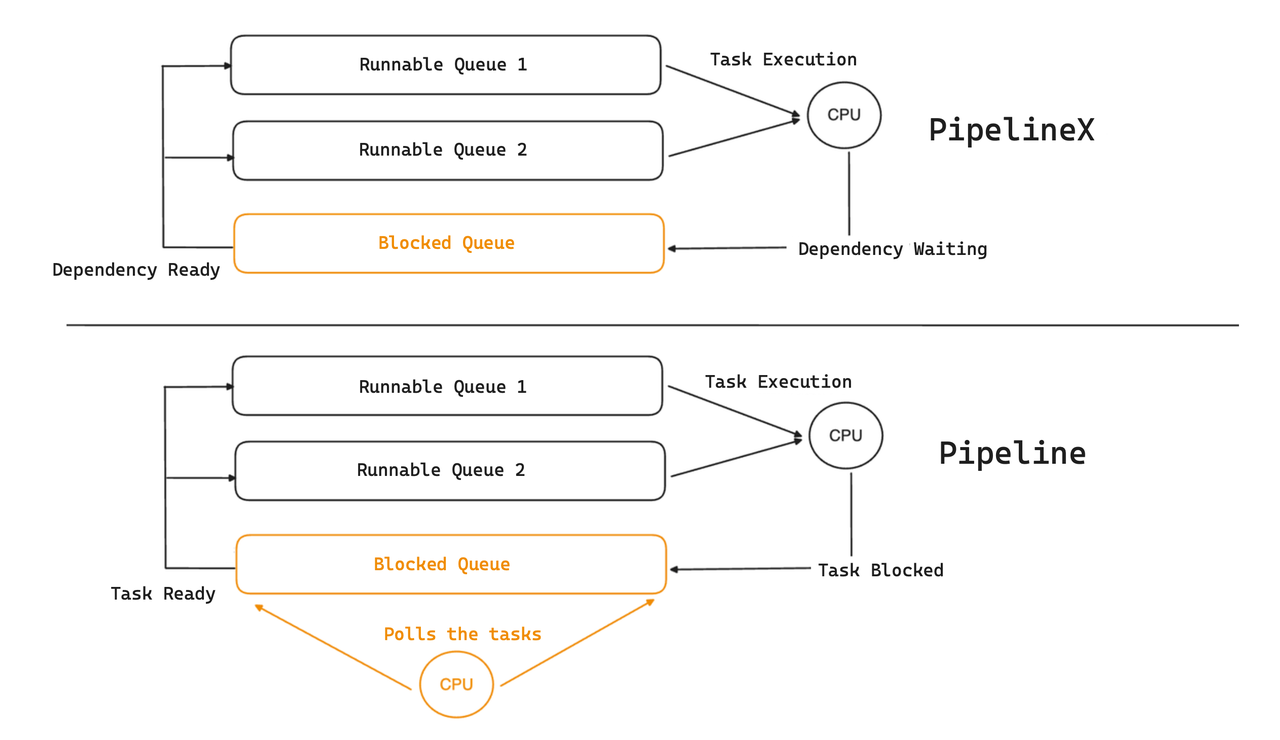
That means PipelineX implements event-driven scheduling. A query execution plan can be depicted as a DAG, where the pipeline tasks are abstracted as nodes and the dependencies as edges. Whether a pipeline task gets executed depends on whether all its associated dependencies have satisfied the requisite conditions.
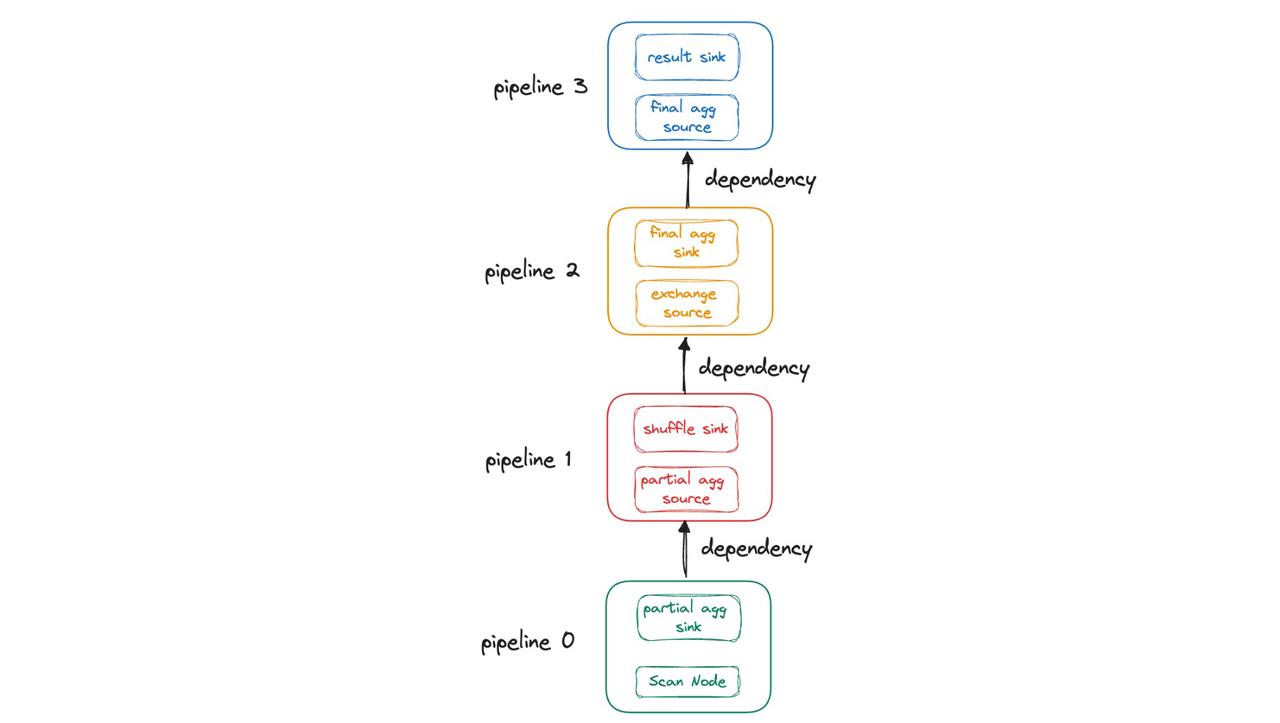
For simplicity of illustration, the above DAG only shows the dependencies between the upstream and downstream pipeline tasks. In fact, all blocking conditions are abstracted as dependencies. The complete execution workflow of a pipeline task is as follows:
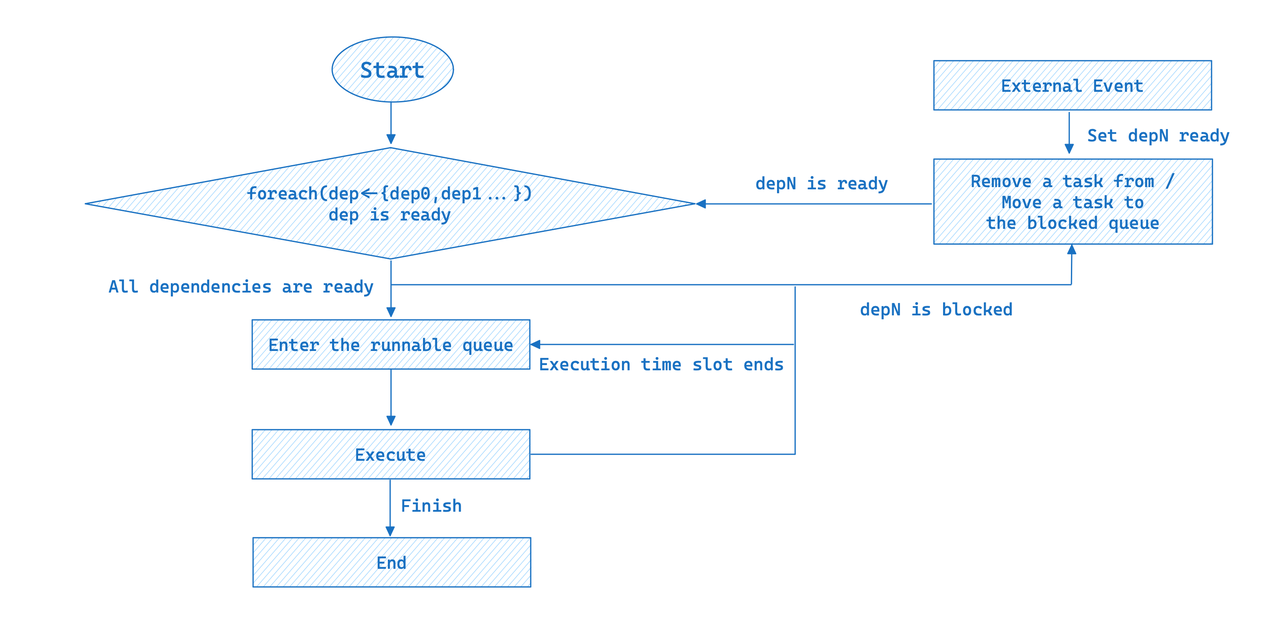
In event-driven execution, a pipeline task will only be executed after all its dependencies satisfy the conditions; otherwise, it will be added to the blocked queue. When an external event arrives, all blocked tasks will be re-evaluated to see if they're runnable.
The event-driven design of PipelineX eliminates the need for a polling thread and thus the consequential performance loss under high cluster loads. Moreover, the encapsulation of dependencies enables a more flexible scheduling framework, making it easier to spill data to disks.
Operator Profile
PipelineX has reorganized the metrics in the operator profiles, adding new ones and obsoleting irrelevant ones. Besides, with the dependencies encapsulated, we monitor how long the dependencies take to get ready by the metric WaitForDependency, so the profile can provide a clear picture of the time spent in each step. These are two examples:
-
Scan Operator: The total execution time of
OLAP_SCAN_OPERATORis 457.750ms, including that spent in data reading by the scanner (436.883ms) and that in actual execution.
OLAP_SCAN_OPERATOR (id=4. table name = Z03_DI_MID):
- ExecTime: 457.750ms
- WaitForDependency[OLAP_SCAN_OPERATOR_DEPENDENCY]Time: 436.883ms- Exchange Source Operator: The execution time of
EXCHANGE_OPERATORis 86.691us. The time spent waiting for data from upstream is 409.256us.
EXCHANGE_OPERATOR (id=3):
- ExecTime: 86.691us
- WaitForDependencyTime: 0ns
- WaitForData0: 409.256usWhat's Next?
From the Volcano Model to the Pipeline Execution Engine, Apache Doris 2.0.0 has overcome the deadlocks under high cluster load and greatly increased CPU utilization. Now, from the Pipeline Execution Engine to PipelineX, Apache Doris 2.1.0 is more production-friendly as it has ironed out the kinks in concurrency, overheads, and operator profile.
What's next in our roadmap is to support spilling data to disk in PipelineX to further improve query speed and system reliability. We also plan to advance further in terms of automation, such as self-adaptive concurrency and auto-execution plan optimization, accompanied by NUMA technologies to harvest better performance from hardware resources.
If you want to talk to the amazing Doris developers who lead these changes, you are more than welcome to join the Apache Doris community.
Published at DZone with permission of Frank Z. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments