Types of Data: A High Level Explanation for Decision Makers
In this article, I'm going to talk about the three different types of data: structured data, semi-structured data, and unstructured data.
Join the DZone community and get the full member experience.
Join For FreeIn this article, I will talk about the different types of data. So, as some of you might be aware, data can be broken down into different types. One such categorization which is very useful when you are building a machine learning pipeline is the following: structured data, semi-structured data, and unstructured data.
So What Is the Difference Between These Types of Data?
Structured Data
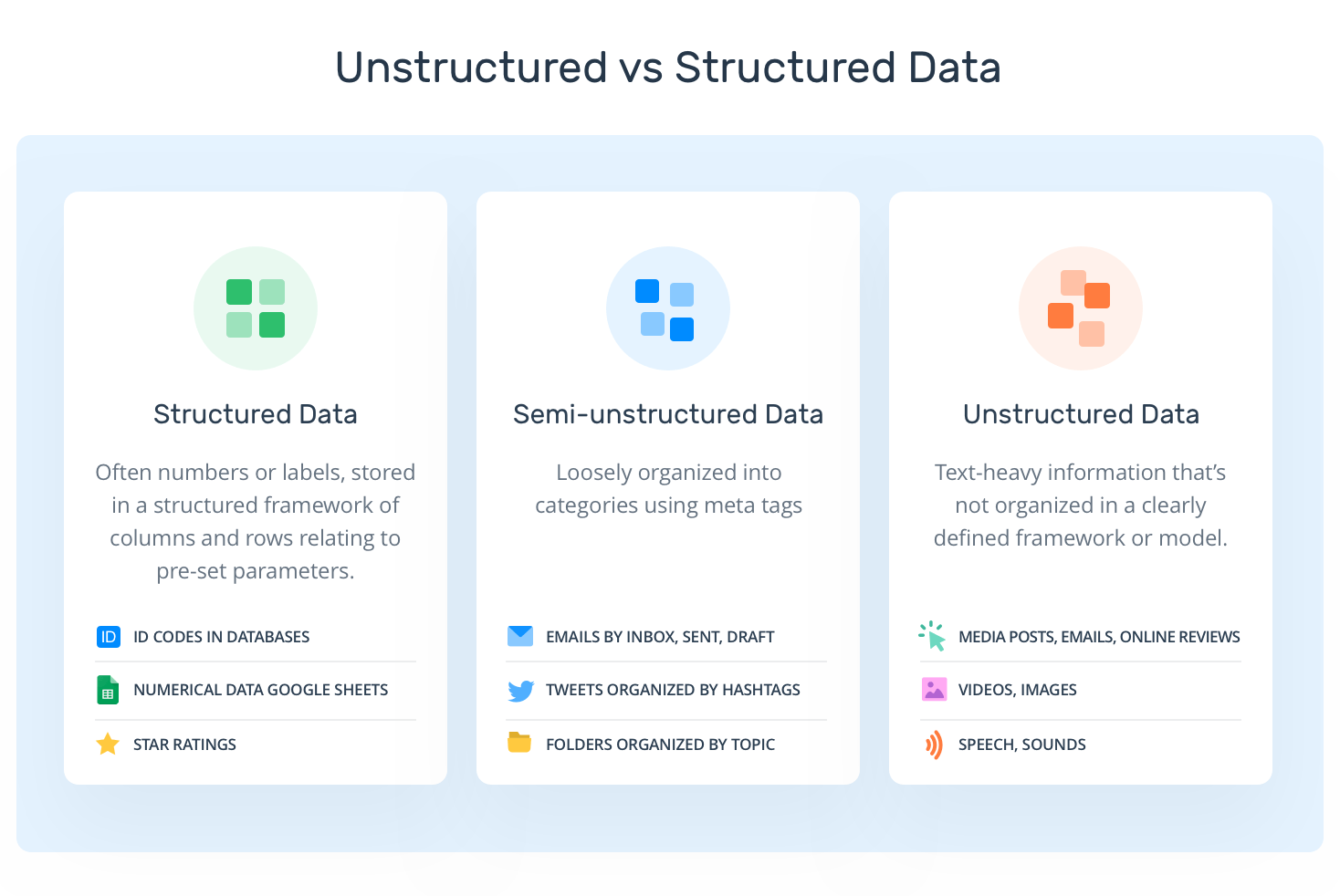
This term refers to data that is organized in a tabular format or in something like a relational database which organizes data in multiple tables which can then be joined together. So structured data presents the easiest type of data to work with. If your data is stored in an SQL database, for example, then most data scientists will find it pretty easy to access the database and then extract insights from the data. That being said, not all databases are created equal. Some databases might be organized in a very bad manner; other databases might be organized in a very easy-to-use manner. But all things being equal, structured data is easy to work with.
If you look deep down into how machine learning pipelines are created, you always need structured data. So even if you have data that is in the same structured or structured format, what algorithms do internally is they steal, they digest this data, and then they transform it into a structured format.

Semi-Structured Data
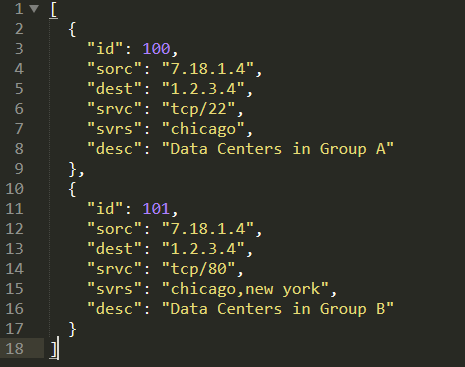 This term refers to data that is not completely organized but not disorganized either. Good example of this is HTML, JSON, and XML. For those who are familiar with HTML or JSON, if you're not, it's very easy to Google JSON and see an example of what a JSON file looks like. You'll very quickly see that JSON seems to follow some kind of structure, and it's the same for HTML. You see something which looks like code, but then again, the JSON or HTML are not fully structured, so they're not organized in the table.
This term refers to data that is not completely organized but not disorganized either. Good example of this is HTML, JSON, and XML. For those who are familiar with HTML or JSON, if you're not, it's very easy to Google JSON and see an example of what a JSON file looks like. You'll very quickly see that JSON seems to follow some kind of structure, and it's the same for HTML. You see something which looks like code, but then again, the JSON or HTML are not fully structured, so they're not organized in the table.
An HTML file or Adjacent file can look very different from some other HTML or JSON file. This means that there are certain freedoms that the developers of those files take, and this can make it somewhat challenging to work with them.
How Do Data Scientists Collect Data From Different Sources?
A data scientist will have to extract information from the semi-structured data and then restructure it into a tabular format. The challenge here is that there are usually many ways to do that. And this step data can be quite time-consuming depending on the kind of data and how the data is organized.
In general, I'm not a huge fan of semi-structured data. As a data scientist, I prefer structured data. Like most data scientists, however, semi-structured data is very useful in domains like social media. Social media is full of text data, image data, video data, and data formats like JSO. Let us store this data alongside meta information.
So, you can store a video, let's say, and then you can store who created this video, comment around this video, etc. This is easier to do using JSON than using SQL, for example. Therefore, semi-structured formats have become so popular in the last ten years. Semi-structured data quite often goes hand in hand with no SQL databases and big data.
Unstructured Data
This term refers to data where there is clearly no structure. For example, data set that consists only of images or videos, or audio is an example of an unstructured data set. So, information in an unstructured data set does not follow a preexisting data model. And this makes it quite challenging to work with because someone might have to go through all the data and understand whether some of the data is potentially noisy or have some other issues which are going to prevent a machine-learning pipeline from being successfully built.
In most cases, unstructured data in the real world is usually you're going to encounter it in two situations.
It's either some sort of open data set or a machine learning competition where someone curates an unstructured data set. You must use this data and try to predict whether a photo contains humans or animals as best as you can. Or the other case where you might encounter structured data is when a data strategy was not designed. Somehow, a company ended up having structured data instead of semi-structured data. Because really, in most scenarios, we expect to see this data alongside some meta information, like when this video showed up, who posted this if we're talking about social media.
How Does a Data Scientist Digest this Type of Data?
I would expect that, in most cases, most of the data should be semi-structured. There are still cases where data might just be unstructured because there is not so much that we can do about it. For example, in customer support, maybe a data set consists of questions and responses. You want to build a bot based on those questions and responses so it can automatically produce answers to different queries.
Well, in this case, probably there's not much you can do to structure the data. In one way or another, you will have to end up with an unstructured data set. But unstructured data, even though it is challenging, quite often can still be successfully analyzed.
In most cases, we're using deep learning. There are deep learning algorithms in order to digest this kind of data. And deep learning has been very successful with data like audio data, natural language data, images, and all this sort of stuff. Regarding these, I've worked in sports analytics in creating predictive models for football injuries and recovery after injuries; I've worked in financial predictions and studied the application of deep learning in manufacturing. The results are very encouraging.
Conclusion
This was a summary of the different types of data that you can encounter in the business recap.
We talked about structured data, the same as structured data and unstructured data. Structured data is usually the low-hanging fruit for a business. And ideally, as a business, you want to have a data strategy that ensures that most of your data is stored in a structured format. The reason is that this makes the life of data scientists much easier, and they will be able to spend more time on valuable tasks instead of just data wrangling.
Schema structured data and unstructured data have started to become to grow in the last 10-15 years. It's the era of big data, after all. But in most cases, you should try to turn structured data and semi-structured data. And once again, semi-structured data is a difficult topic because of the kind of database you need to choose and how you should organize the different fields, and for what purpose.
Published at DZone with permission of Stylianos Kampakis. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments