Using AWS Data Lake and S3 With SQL Server: A Detailed Guide With Research Paper Dataset Example
The integration of AWS Data Lake and Amazon S3 with SQL Server provides the ability to store data at any scale and leverage advanced analytics capabilities.
Join the DZone community and get the full member experience.
Join For FreeThe integration of AWS Data Lake and Amazon S3 with SQL Server provides the ability to store data at any scale and leverage advanced analytics capabilities. This comprehensive guide will walk you through the process of setting up this integration, using a research paper dataset as a practical example.
What Is a Data Lake?
A data lake serves as a centralized repository for storing both structured and unstructured data, regardless of its size. It empowers users to perform a wide range of analytics, including visualizations, big data processing, real-time analytics, and machine learning.
Amazon S3: The Foundation of AWS Data Lake
Amazon Simple Storage Service (S3) is an object storage service that offers scalability, data availability, security, and high performance. It plays a critical role in the data lake architecture by providing a solid foundation for storing both raw and processed data.
Why Integrate AWS Data Lake and S3 With SQL Server?
- Achieve scalability by effectively managing extensive amounts of data.
- Save on costs by storing data at a reduced rate in comparison to conventional storage methods.
- Utilize advanced analytics capabilities to conduct intricate queries and analytics on vast datasets.
- Seamlessly integrate data from diverse sources to gain comprehensive insights.
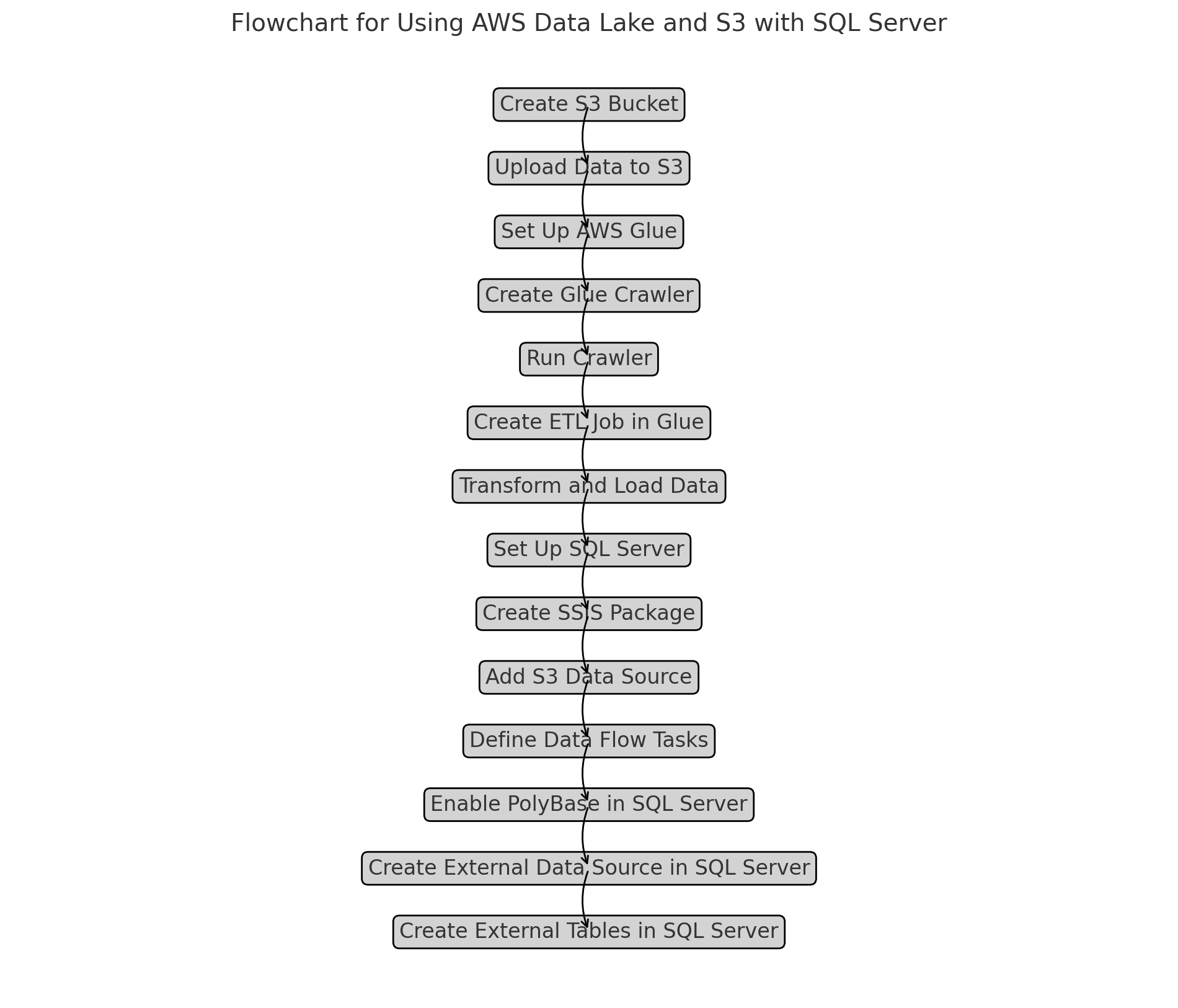
Step-By-Step Guide
1. Setting Up AWS Data Lake and S3
Step 1: Create an S3 Bucket
- Log in to AWS Management Console.
- Navigate to S3 and click on "Create bucket."
- Name the bucket: Use a unique name, e.g.,
researchpaperdatalake. - Configure settings:
- Versioning: Enable versioning to keep multiple versions of an object.
- Encryption: Enable serverside encryption to protect your data.
- Permissions: Set appropriate permissions using bucket policies and IAM roles.
Step 2: Ingest Data Into S3
For our example, we have a dataset of research papers stored in CSV files.
- Upload data manually.
- Go to the S3 bucket.
- Click "Upload" and select your CSV files.
- Automate data ingestion.
- Use AWS CLI:
aws s3 cp path/to/local/research_papers.csv s3://researchpaperdatalake/raw/
3. Organize data:
- Create folders such as
raw/,processed/, andmetadata/to organize the data.
2. Set Up AWS Glue
AWS Glue is a managed ETL service that makes it easy to prepare and load data.
- Create a Glue crawler.
- Navigate to AWS Glue in the console.
- Create a new crawler: Name it
researchpapercrawler. - Data store: Choose S3 and specify the bucket path
(`s3://researchpaperdatalake/raw/`). - IAM role: Select an existing IAM role or create a new one with the necessary permissions.
- Run the crawler: It will scan the data and create a table in the Glue Data Catalog.
- Create an ETL job.
- Transform data: Write a PySpark or Python script to clean and preprocess the data.
- Load data: Store the processed data back in S3 or load it into a database.
3. Integrate With SQL Server
Step 1: Setting Up SQL Server
Ensure your SQL Server instance is running and accessible. This can be onpremises, on an EC2 instance, or using Amazon RDS for SQL Server.
Step 2: Using SQL Server Integration Services (SSIS)
SQL Server Integration Services (SSIS) is a powerful ETL tool.
- Install and configure SSIS: Ensure you have SQL Server Data Tools (SSDT) and SSIS installed.
- Create a new SSIS package:
- Open SSDT and create a new Integration Services project.
- Add a new package for the data import process.
- Add an S3 data source:
- Use third-party SSIS components or custom scripts to connect to your S3 bucket. Tools like the Amazon Redshift and S3 connectors can be useful.
- Example: Use the ZappySys SSIS Amazon S3 Source component to connect to your S3 bucket.
- Use third-party SSIS components or custom scripts to connect to your S3 bucket. Tools like the Amazon Redshift and S3 connectors can be useful.
- Data Flow tasks:
- Extract Data: Use the S3 source component to read data from the CSV files.
- Transform Data: Use transformations like Data Conversion, Derived Column, etc.
- Load Data: Use an OLE DB Destination to load data into SQL Server.
Step 3: Direct Querying With SQL Server PolyBase
PolyBase allows you to query external data stored in S3 directly from SQL Server.
- Enable PolyBase: Install and configure PolyBase on your SQL Server instance.
- Create an external data source: Define an external data source pointing to your S3 bucket.
CREATE EXTERNAL DATA SOURCE S3DataSource
WITH (
TYPE = HADOOP,
LOCATION = 's3://researchpaperdatalake/raw/',
CREDENTIAL = S3Credential
);3. Create external tables: Define external tables that reference the data in S3.
CREATE EXTERNAL TABLE ResearchPapers (
PaperID INT,
Title NVARCHAR(255),
Authors NVARCHAR(255),
Abstract NVARCHAR(MAX),
PublishedDate DATE
)
WITH (
LOCATION = 'research_papers.csv',
DATA_SOURCE = S3DataSource,
FILE_FORMAT = CSVFormat
);
4. Define file format:
CREATE EXTERNAL FILE FORMAT CSVFormat
WITH (
FORMAT_TYPE = DELIMITEDTEXT,
FORMAT_OPTIONS (
FIELD_TERMINATOR = ',',
STRING_DELIMITER = '"'
)
);Flow Diagram
Best Practices
- Data partitioning: Partition your data in S3 to improve query performance and manageability.
- Security: Use AWS IAM roles and policies to control access to your data. Encrypt data at rest and in transit.
- Monitoring and auditing: Enable logging and monitoring using AWS CloudWatch and AWS CloudTrail to track access and usage.
Conclusion
The combination of AWS Data Lake and S3 with SQL Server offers a robust solution for handling and examining extensive datasets. By utilizing AWS's scalability and SQL Server's strong analytics features, organizations can establish a complete data framework that facilitates advanced analytics and valuable insights. Whether data is stored in S3 in its raw form or intricate queries are executed using PolyBase, this integration equips you with the necessary resources to excel in a data-centric environment.
Opinions expressed by DZone contributors are their own.
Comments