Vector Databases for Generative AI Applications
This post details a recent talk from a session at GIDS 2024 and provides a deeper look into the fundamentals of vector databases for Generative AI applications.
Join the DZone community and get the full member experience.
Join For FreeI first shared this blog from my session (at GIDS 2024). If you attended it, thank you for coming and I hope you found it useful! If not, well, you have the resources and links anyway – I have written out the talk so that you can follow along with the slides if you need more context.
Hopefully, the folks at GIDS will publish the video as well. I will add the link once it's available.
Key Info
- Slides available here
- GitHub repository - Code and instructions on how to get the demo up and running
Summarized Version of the Talk
I had 30-mins – so, I kept it short and sweet!
Setting the Context
Foundation models (FMs) are the heart of generative AI. These models are pre-trained on vast amounts of data. Large language models (LLMs) are a class of FMs; for instance, the Claude family from Anthropic, Llama from Meta, etc.
You generally access these using dedicated platforms; for example, Amazon Bedrock, which is a fully managed service with a wide range of models accessible via APIs. These models are pretty powerful, and they can be used standalone to build generative AI apps.
So Why Do We Need Vector Databases?
To better understand this, let's take a step back and talk about the limitations of LLMs. I will highlight a few common ones.
LLM Limitations
- Knowledge cut-off: The knowledge of these models is often limited to the data that was current at the time it was pre-trained or fine-tuned.
- Hallucination: Sometimes, these models provide an incorrect response, quite “confidently."
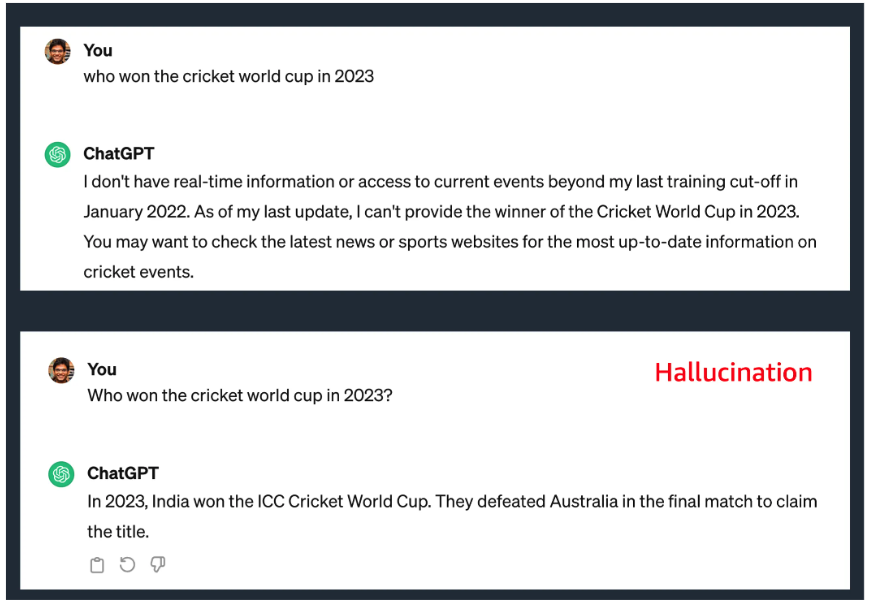
Lack of Access To External Data Sources
Another reason is the lack of access to external data sources.
Think about it: You can set up an AWS account and start using models on Amazon Bedrock. But, if you want to build generative AI applications that are specific to your business needs, you need domain or company-specific private data (for example, a customer service chatbot that can access customer details, order info, etc.).
Now, it's possible to train or fine-tune these models with your data – but it's not trivial or cost-effective. However, there are techniques to work around these constraints – RAG (discussed later) being one of them, and vector databases play a key role.
Dive Into Vector Databases
Before we get into it, let's understand the following:
What Is a Vector?
In simple terms, vectors are numerical representations of text.
- There is input text (also called prompt).
- You pass it through something called an embedding model - think of it as a stateless function.
- You get an output which is an array of floating-point numbers.
What’s important to understand is that Vectors capture semantic meaning, so they can be used for relevancy or context-based search, rather than simple text search.

Types of Vector Databases
I tend to categorize Vector databases into two types:
- Vector data type support within existing databases, such as PostgreSQL, Redis, OpenSearch, MongoDB, Cassandra, etc.
- Specialized vector databases, like Pinecone, Weaviate, Milvus, Qdrant, ChromaDB, etc.
This field is also moving very fast and I’m sure we will see a lot more in the near future!
Now you can run these specialized vector stores on AWS, via their dedicated cloud offerings. But I want to quickly give you a glimpse of the choices in terms of the first category that I referred to.
The following are supported as native AWS database(s):
- Amazon OpenSearch service
- Amazon Aurora with PostgreSQL compatibility
- Amazon DocumentDB (with MongoDB compatibility)
- Amazon MemoryDB for Redis which currently has Vector search in preview (at the time of writing)
Vector Databases in Generative AI Solutions
Here is a simplified view of where vector databases sit in generative AI solutions:
- You take your domain-specific data and split/chunk them up.
- Pass them through an embedding model: this gives you these vectors or embeddings.
- Store these embeddings in a vector database.
- Then, there are applications that execute semantic search queries and combine them in various ways (RAG being one of them).
Demo 1 (of 3): Semantic Search With OpenSearch and LangChain
Find the details on the GitHub repository linked earlier.
RAG: Retrieval Augmented Generation
We covered the limitations of LLM – knowledge cut-off, hallucination, no access to internal data, etc. Of course, there are multiple ways to overcome this.
- Prompt-engineering techniques: Zero-shot, few-shot, etc., - Sure this is cost-effective, but how would this apply to domain-specific data?
- Fine-tuning: Take an existing LLM and train it using a specific dataset. But what about the infra and costs involved? Do you want to become a model development company or focus on your core business?
These are just a few examples.
RAG Technique Adopts a Middle Ground
There are two key parts to a RAG workflow:
- Part 1: Data ingestion is where you take your source data (PDF, text, images, etc.), break it down into chunks, pass it through an embedding model, and store it in the vector database.
- Part 2: This involves the end-user application (e.g., a chatbot). The user sends a query – this input is converted to vector embedding using the same (embedding) model that was used for the source data. We then execute a semantic or similarity search to get the top-N closest results.
That’s not all.
- Part 3: These results, also referred to as ”context,” are then combined with the user input and a specialized prompt. Finally, this is sent to an LLM – note this is not the embedding model, this is a large language model. The added context in the prompt helps the model provide a more accurate and relevant response to the user’s query.
Demo 2 (of 3): RAG With OpenSearch and LangChain
Find the details in the GitHub repository linked earlier.

Fully-Managed RAG Experience: Knowledge Bases for Amazon Bedrock
Another approach is to have a managed solution to take care of the heavy lifting. For example, if you use Amazon Bedrock, then Knowledge Bases can make RAG easier and more manageable. It supports the entire RAG workflow, from ingestion to retrieval and prompt augmentation.
It supports multiple vector stores to store vector embedding data.

Demo 3 (Of 3): Full-Managed RAG Knowledge Bases for Amazon Bedrock
Find the details in the GitHub repository linked earlier.

Now how do we build RAG applications using this?
For application integration, this is exposed by APIs:
- RetrieveAndGenerate: Call the API, get the response - that's it. Everything (query embedding, semantic search, prompt engineering, LLM orchestration) is handled!
- Retrieve: For custom RAG workflows, where you simply extract the top-N responses (like semantic search) and integrate the rest as per your choice.
Where Do I Learn More?
- Documentation is a great place to start! Specifically, "Knowledge bases for Amazon Bedrock"
- Code samples for Amazon Bedrock
- Lots of content and practical solutions in the generative AI community space!
- Ultimately, there is no replacement for hands-on learning. Head over to Amazon Bedrock and start building!
Wrapping Up
And, that's it. Like I said, I had 30-mins and I kept it short and sweet! This area is evolving very quickly. This includes vector databases, LLMs (there is one every week - feels like the JavaScript frameworks era!), and frameworks (like LangChain, etc.). It's hard to keep up but remember: the fundamentals are the same. The key is to grasp them - hopefully, this helps with some of it.
Happy building!
Published at DZone with permission of Abhishek Gupta, DZone MVB. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments