Machine learning anti-patterns are commonly occurring solutions to problems that appear to be the right thing to do, but ultimately lead to bad outcomes or suboptimal results. They are the pitfalls or mistakes that are commonly made in the development or application of ML models. These mistakes can lead to poor performance, biases, overfitting, or other problems.
Phantom Menace
The term "Phantom Menace" comes from instances when differences between training and test data may not be immediately apparent during the development and evaluation phase, but it can become a problem when the model is deployed in the real world.
The training/serving skew occurs when the statistical properties of the training data are different from the distribution of the data that the model is exposed to during inference. This difference can result in poor performance when the model is deployed, even if it performs well during training. For example, if the training data for an image classification model consists mostly of daytime photos, but the model is later deployed to classify nighttime photos, the model may not perform well due to this mismatch in data distributions.
To mitigate training/serving skew, it is important to ensure that the training data is representative of the data that the model will encounter during inference, and to monitor the model's performance in production to detect any performance degradation caused by distributional shift. Techniques like data augmentation, transfer learning, and model calibration can also help improve the model's ability to generalize to new data.
The Sentinel
The "Sentinel" anti-pattern is a technique used to validate models or data in an online environment before deploying them to production. It is a separate model or set of rules that is used to evaluate the performance of the primary model or data in a production environment. The purpose is to act as a "safety net" and prevent any incorrect or undesirable outputs from being released into the real world. It can detect issues such as data drift, concept drift, or performance degradation and provide alerts to the development team to investigate and resolve the issue before it causes harm.
For example, in the context of an online recommendation system, a sentinel model can be used to evaluate the recommendations made by the primary model before they are shown to the user. If the sentinel model detects that the recommendations are significantly different from what is expected, it can trigger an alert for the development team to investigate and address any issues before the recommendations are shown to the user.
Figure 1: The Sentinel
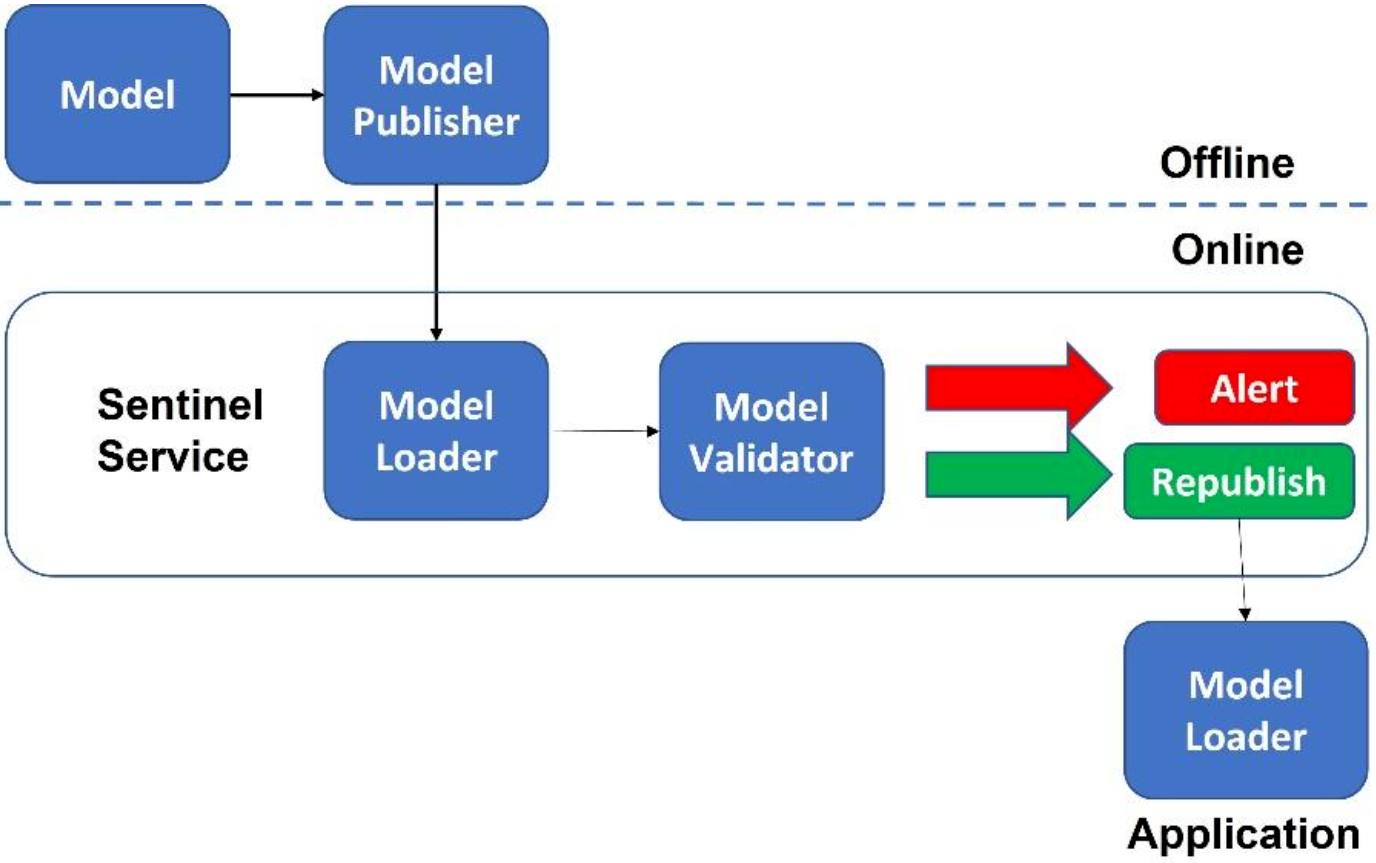
The use of a sentinel can help mitigate risks associated with model or data degradation, concept drift, and other issues that can occur when deploying machine learning models in production. However, it is important to design the sentinel model carefully to ensure that it provides adequate protection without unnecessarily delaying the deployment of the primary model.
The Hulk
The "Hulk" anti-pattern is a technique where the entire model training, validation, and evaluation process is performed offline, and only the final output or prediction is published for use in a production environment. This approach is also sometimes referred to as offline precompute.
"Hulk" comes from the idea that the model is developed and tested in isolation, like the character Bruce Banner who becomes the Hulk when isolated from others.
Figure 2: The Hulk
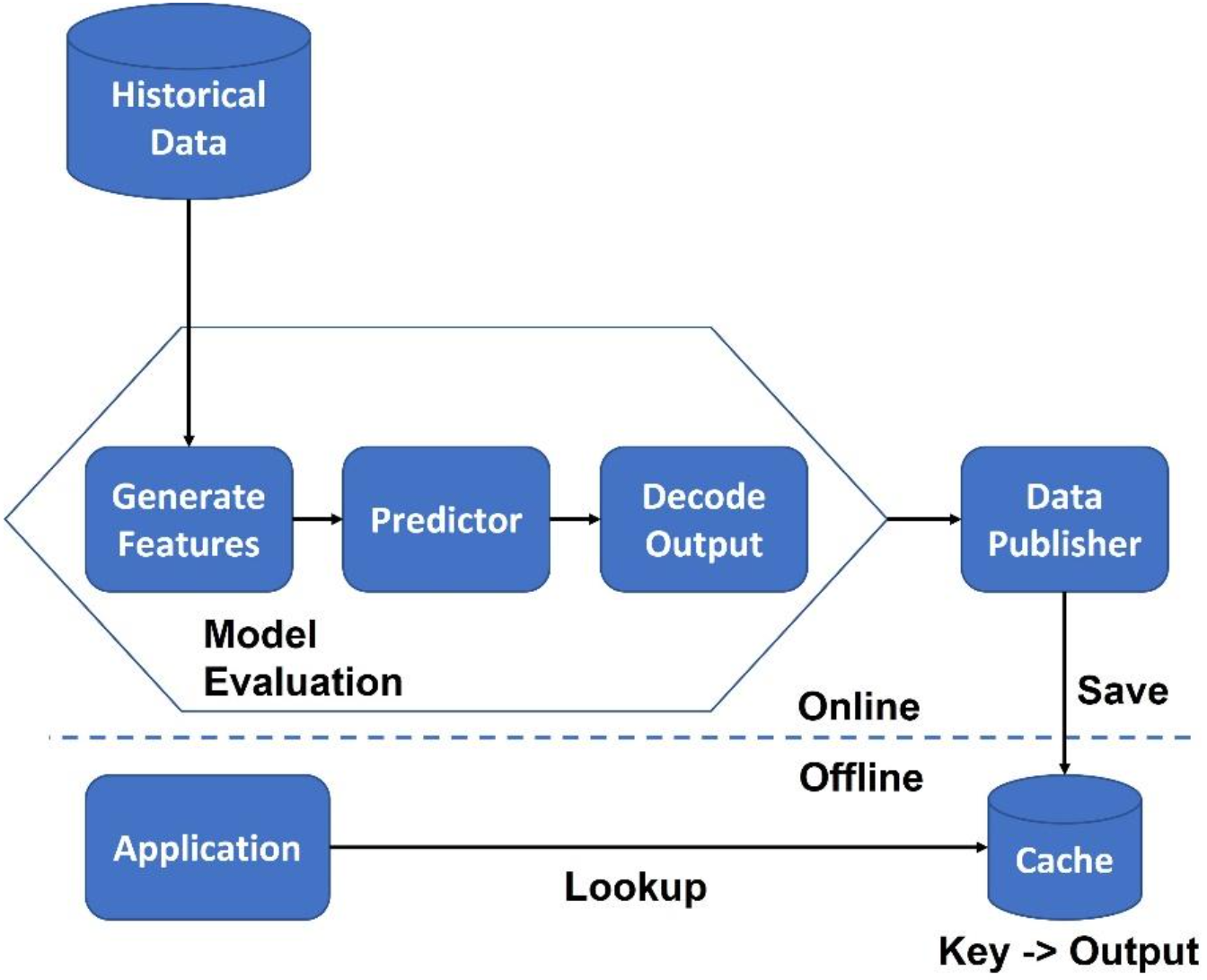
To mitigate the risks associated with the Hulk anti-pattern, it is important to validate the model's performance in a production environment and continuously monitor the data and model performance to detect and address any issues that may arise. This can include techniques such as data logging, monitoring, and feedback mechanisms to enable the model to adapt and improve over time.
The Lumberjack
The "Lumberjack" (also known as feature logging) anti-pattern refers to a technique where features are logged online from within an application, and the resulting logs are used to train ML models. Similar to how lumberjacks cut down trees, process them into logs, and then use the logs to build structures, in feature logging, the input data is "cut down" into individual features that are then processed and used to build a model, as shown in Figure 3.
Figure 3: The Lumberjack
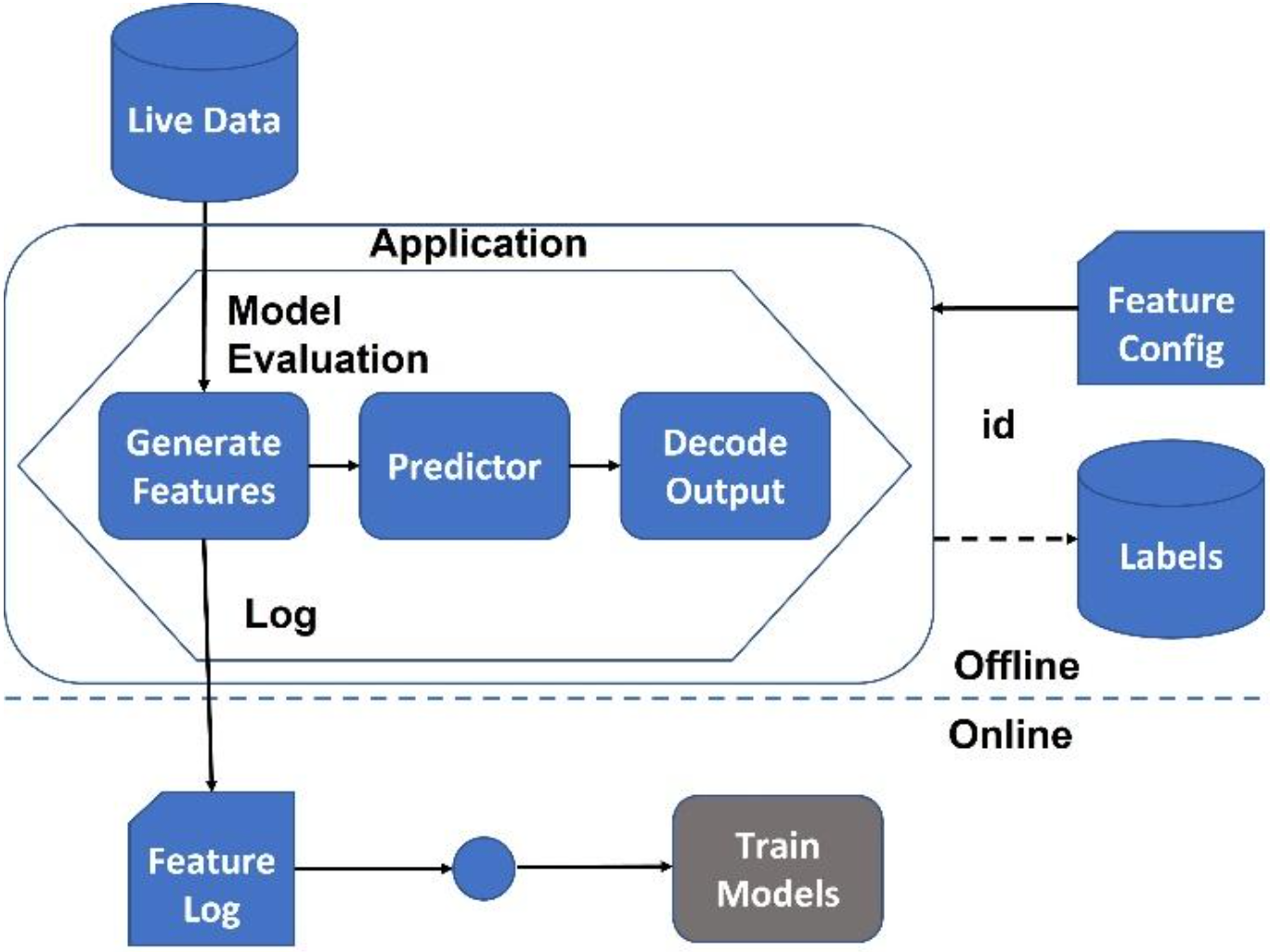
To mitigate the risks associated with the Lumberjack anti-pattern, it is important to carefully design the feature logging process to capture relevant information and avoid biases or errors. This can include techniques such as feature selection, feature engineering, and data validation to ensure that the logged features accurately represent the underlying data. It is also important to validate the model's performance in a production environment and continuously monitor the data and model performance to detect and address any issues that may arise.
The Time Machine
The "Time Machine" anti-pattern is a technique where historical data is used to train a model, and the resulting model is then used to make predictions about future data (hence the name). This approach is also known as time-based modeling or temporal modeling.
To mitigate the risks associated with the Time Machine anti-pattern, it is important to carefully design the modeling process to capture changes in the underlying data over time and to validate the model's performance on recent data. This can include techniques such as using sliding windows, incorporating time-dependent features, and monitoring the model's performance over time.
Techniques to Detect Machine Learning Anti-Patterns
The following techniques help to identify and mitigate common mistakes and pitfalls that can arise in the development and deployment of ML models.
Table 7
Technique |
Description |
Cross-validation |
- Assess an ML model's performance by splitting the dataset into training and testing sets.
- Detect overfitting and underfitting, which are common anti-patterns in ML.
|
Bias detection |
- Bias is a common anti-pattern in ML that can lead to unfair or inaccurate predictions.
- ML techniques like fairness metrics, demographic parity, and equalized odds can be used to detect and mitigate bias in models.
|
Feature selection |
- Identify the most important features or variables in a dataset.
- Detect and address anti-patterns like irrelevant features and feature redundancy, which can lead to overfitting and reduced model performance.
|
Model interpretability |
- ML techniques like decision trees, random forests, and LIME can be used to provide interpretability and transparency to ML models.
- Detect and address anti-patterns like black-box models, which are difficult to interpret and can lead to reduced trust and performance.
|
Performance metrics |
- ML models can be evaluated using a variety of performance metrics, including accuracy, precision, recall, F1 score, and AUC-ROC.
- Monitoring these metrics over time can help detect changes in model performance and identify anti-patterns like model drift and overfitting.
|

{{ parent.title || parent.header.title}}
{{ parent.tldr }}
{{ parent.linkDescription }}
{{ parent.urlSource.name }}